A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B
Jemin Lee, Sihyeong Park, Jinse Kwon, Jihun Oh, Yongin Kwon
2024-09-18
Summary
This paper evaluates how well different quantization methods work for large language models (LLMs) that have been fine-tuned with instructions, specifically looking at models up to 405 billion parameters.
What's the problem?
Previous studies on quantized LLMs have only looked at a few basic performance metrics and older datasets, making it unclear how well these models perform in real-world tasks. Additionally, newer large models like Llama 3.1 haven't been thoroughly tested to see how they handle quantization, which is important for reducing their size and improving efficiency without losing performance.
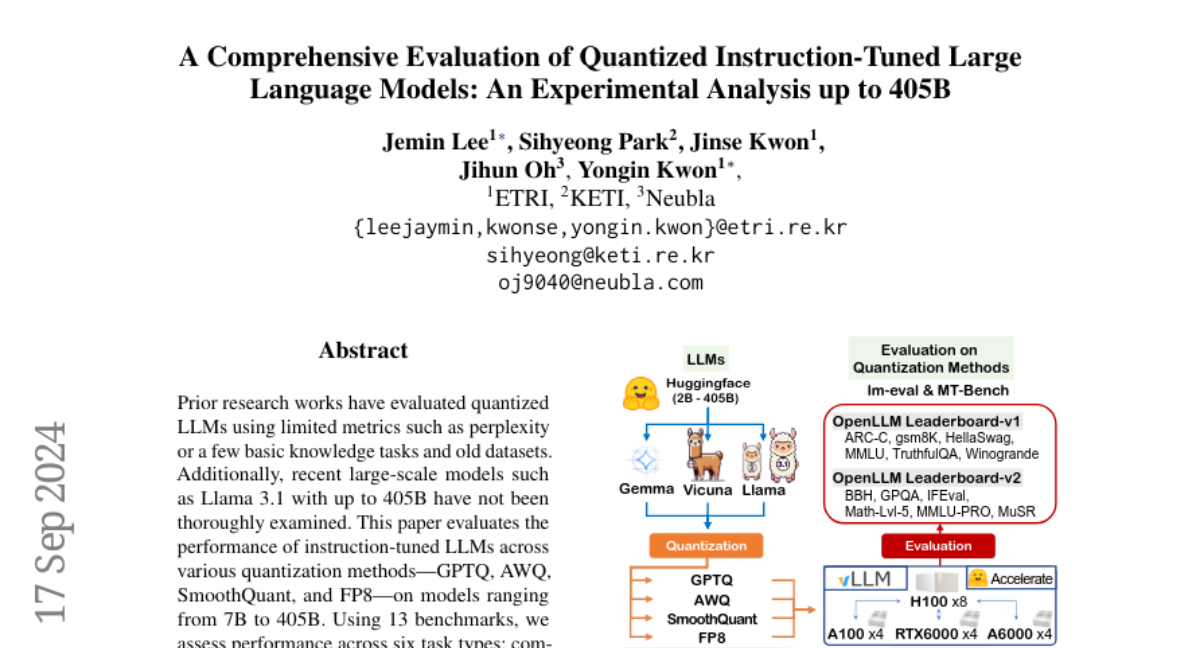
What's the solution?
The researchers conducted a comprehensive evaluation of instruction-tuned LLMs using various quantization methods, such as GPTQ and AWQ, across multiple benchmarks. They tested models ranging from smaller ones (7 billion parameters) to very large ones (405 billion parameters) on different tasks like question answering and dialogue. Their findings showed that larger quantized models often perform better than smaller non-quantized ones and that the choice of quantization method significantly affects performance. They also discovered that the difficulty of the tasks did not greatly impact the accuracy of the quantized models.
Why it matters?
This research is significant because it provides a deeper understanding of how quantization affects the performance of large language models, especially in practical applications. By identifying effective quantization strategies, this work can help improve the efficiency of AI systems, making them faster and cheaper to run while maintaining high-quality results.
Abstract
Prior research works have evaluated quantized LLMs using limited metrics such as perplexity or a few basic knowledge tasks and old datasets. Additionally, recent large-scale models such as Llama 3.1 with up to 405B have not been thoroughly examined. This paper evaluates the performance of instruction-tuned LLMs across various quantization methods (GPTQ, AWQ, SmoothQuant, and FP8) on models ranging from 7B to 405B. Using 13 benchmarks, we assess performance across six task types: commonsense Q\&A, knowledge and language understanding, instruction following, hallucination detection, mathematics, and dialogue. Our key findings reveal that (1) quantizing a larger LLM to a similar size as a smaller FP16 LLM generally performs better across most benchmarks, except for hallucination detection and instruction following; (2) performance varies significantly with different quantization methods, model size, and bit-width, with weight-only methods often yielding better results in larger models; (3) task difficulty does not significantly impact accuracy degradation due to quantization; and (4) the MT-Bench evaluation method has limited discriminatory power among recent high-performing LLMs.