AnyDressing: Customizable Multi-Garment Virtual Dressing via Latent Diffusion Models
Xinghui Li, Qichao Sun, Pengze Zhang, Fulong Ye, Zhichao Liao, Wanquan Feng, Songtao Zhao, Qian He
2024-12-06
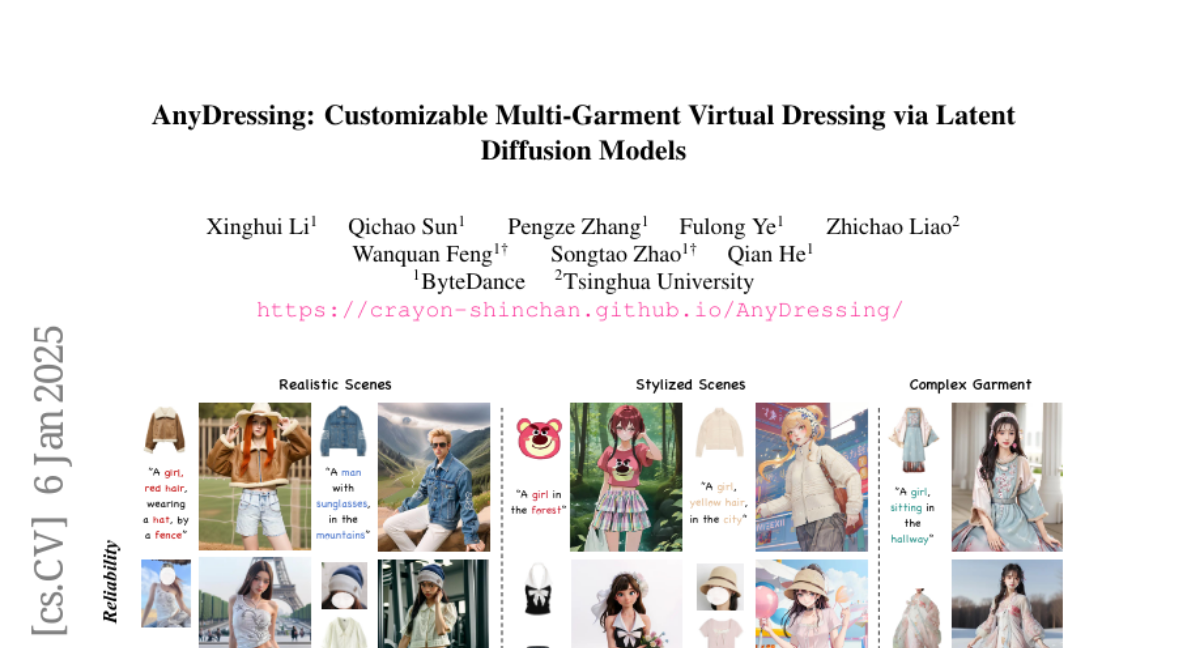
Summary
This paper talks about AnyDressing, a new method that allows users to virtually dress characters in any combination of clothes using advanced image generation techniques, making online shopping more customizable and realistic.
What's the problem?
Current methods for generating images of clothing often struggle to accurately combine different outfits and maintain the details of each garment. This makes it hard for users to see how various clothes would look together, which limits their shopping experience.
What's the solution?
The authors developed AnyDressing, which uses two main networks: GarmentsNet for extracting detailed clothing features and DressingNet for generating customized images. They created a way to process garment textures separately to avoid confusion and designed special mechanisms to accurately place multiple garments on a character. This allows users to see how different outfits look together while ensuring high quality and detail in the images.
Why it matters?
This research is important because it enhances the virtual dressing experience, allowing users to mix and match outfits easily. By improving how clothes are visualized online, AnyDressing can help reduce return rates in online shopping and provide a more satisfying experience for customers looking to find the perfect outfit.
Abstract
Recent advances in garment-centric image generation from text and image prompts based on diffusion models are impressive. However, existing methods lack support for various combinations of attire, and struggle to preserve the garment details while maintaining faithfulness to the text prompts, limiting their performance across diverse scenarios. In this paper, we focus on a new task, i.e., Multi-Garment Virtual Dressing, and we propose a novel AnyDressing method for customizing characters conditioned on any combination of garments and any personalized text prompts. AnyDressing comprises two primary networks named GarmentsNet and DressingNet, which are respectively dedicated to extracting detailed clothing features and generating customized images. Specifically, we propose an efficient and scalable module called Garment-Specific Feature Extractor in GarmentsNet to individually encode garment textures in parallel. This design prevents garment confusion while ensuring network efficiency. Meanwhile, we design an adaptive Dressing-Attention mechanism and a novel Instance-Level Garment Localization Learning strategy in DressingNet to accurately inject multi-garment features into their corresponding regions. This approach efficiently integrates multi-garment texture cues into generated images and further enhances text-image consistency. Additionally, we introduce a Garment-Enhanced Texture Learning strategy to improve the fine-grained texture details of garments. Thanks to our well-craft design, AnyDressing can serve as a plug-in module to easily integrate with any community control extensions for diffusion models, improving the diversity and controllability of synthesized images. Extensive experiments show that AnyDressing achieves state-of-the-art results.