Atlas: Multi-Scale Attention Improves Long Context Image Modeling
Kumar Krishna Agrawal, Long Lian, Longchao Liu, Natalia Harguindeguy, Boyi Li, Alexander Bick, Maggie Chung, Trevor Darrell, Adam Yala
2025-03-19
Summary
This paper introduces Atlas, a new method for AI to process large images more efficiently.
What's the problem?
AI struggles to handle extremely large images because it takes a lot of computing power and memory.
What's the solution?
Atlas uses a technique called Multi-Scale Attention, which breaks down the image into different sizes and then uses connections between these sizes to process the image more efficiently.
Why it matters?
This work matters because it allows AI to work with very large images faster and with less memory, which is important for applications like analyzing satellite images or high-resolution medical scans.
Abstract
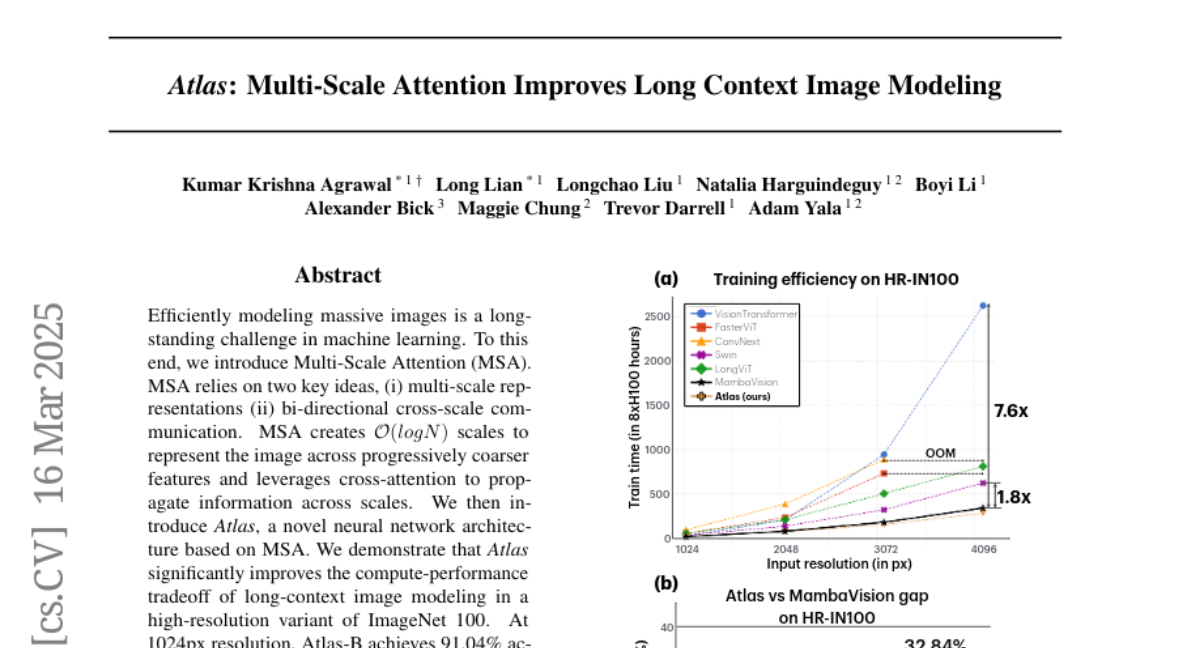
Efficiently modeling massive images is a long-standing challenge in machine learning. To this end, we introduce Multi-Scale Attention (MSA). MSA relies on two key ideas, (i) multi-scale representations (ii) bi-directional cross-scale communication. MSA creates O(log N) scales to represent the image across progressively coarser features and leverages cross-attention to propagate information across scales. We then introduce Atlas, a novel neural network architecture based on MSA. We demonstrate that Atlas significantly improves the compute-performance tradeoff of long-context image modeling in a high-resolution variant of ImageNet 100. At 1024px resolution, Atlas-B achieves 91.04% accuracy, comparable to ConvNext-B (91.92%) while being 4.3x faster. Atlas is 2.95x faster and 7.38% better than FasterViT, 2.25x faster and 4.96% better than LongViT. In comparisons against MambaVision-S, we find Atlas-S achieves 5%, 16% and 32% higher accuracy at 1024px, 2048px and 4096px respectively, while obtaining similar runtimes. Code for reproducing our experiments and pretrained models is available at https://github.com/yalalab/atlas.