BPO: Supercharging Online Preference Learning by Adhering to the Proximity of Behavior LLM
Wenda Xu, Jiachen Li, William Yang Wang, Lei Li
2024-06-19
Summary
This paper introduces a new method called BPO (Behavior LLM Proximity Optimization) that aims to improve how large language models (LLMs) learn user preferences. It focuses on making the learning process more efficient by using a model that mimics human behavior as a guide.
What's the problem?
Many existing methods for training language models to understand user preferences rely on pre-collected data and do not adapt well to new information. This can slow down the learning process and make it less effective. Additionally, while some models can benefit from online data, they often do not utilize it in the best way, leading to suboptimal performance.
What's the solution?
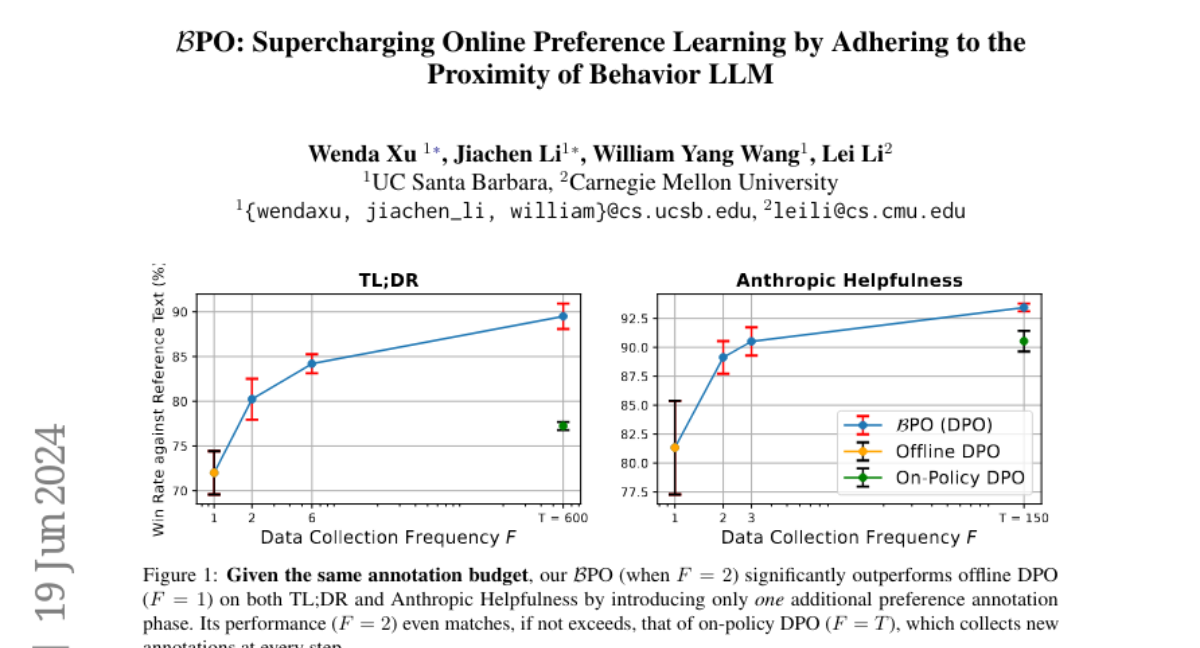
To solve this problem, the authors developed BPO, which allows the preference learning model to stay close to a behavior LLM that collects training samples. By doing this, BPO creates a 'trust region' where the model can effectively learn user preferences. The researchers conducted experiments and found that BPO significantly improved performance across various tasks, increasing accuracy rates when compared to traditional methods. For example, they showed improvements from 72.0% to 80.2% on one task and from 82.2% to 89.1% on another when using BPO.
Why it matters?
This research is important because it enhances how AI systems can learn and adapt to user preferences more effectively. By improving the efficiency of preference learning, BPO could help create more personalized AI applications, such as recommendation systems for movies, music, or products, making them better at understanding what users want.
Abstract
Direct alignment from preferences (DAP) has emerged as a promising paradigm for aligning large language models (LLMs) to human desiderata from pre-collected, offline preference datasets. While recent studies indicate that existing offline DAP methods can directly benefit from online training samples, we highlight the need to develop specific online DAP algorithms to fully harness the power of online training. Specifically, we identify that the learned LLM should adhere to the proximity of the behavior LLM, which collects the training samples. To this end, we propose online Preference Optimization in proximity to the Behavior LLM (BPO), emphasizing the importance of constructing a proper trust region for LLM alignment. We conduct extensive experiments to validate the effectiveness and applicability of our approach by integrating it with various DAP methods, resulting in significant performance improvements across a wide range of tasks when training with the same amount of preference data. Even when only introducing one additional data collection phase, our online BPO improves its offline DAP baseline from 72.0% to 80.2% on TL;DR and from 82.2% to 89.1% on Anthropic Helpfulness in terms of win rate against human reference text.