Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
Tiancheng Gu, Kaicheng Yang, Ziyong Feng, Xingjun Wang, Yanzhao Zhang, Dingkun Long, Yingda Chen, Weidong Cai, Jiankang Deng
2025-04-25
Summary
This paper talks about a new approach for teaching AI models to understand and connect information from different types of data, like text, images, and audio, by creating a universal way to represent all of them together.
What's the problem?
The problem is that most AI models are really good at handling one kind of data, like just text or just images, but they struggle when they need to work with several types at once. This makes it hard for them to solve complex tasks that involve mixing information from different sources.
What's the solution?
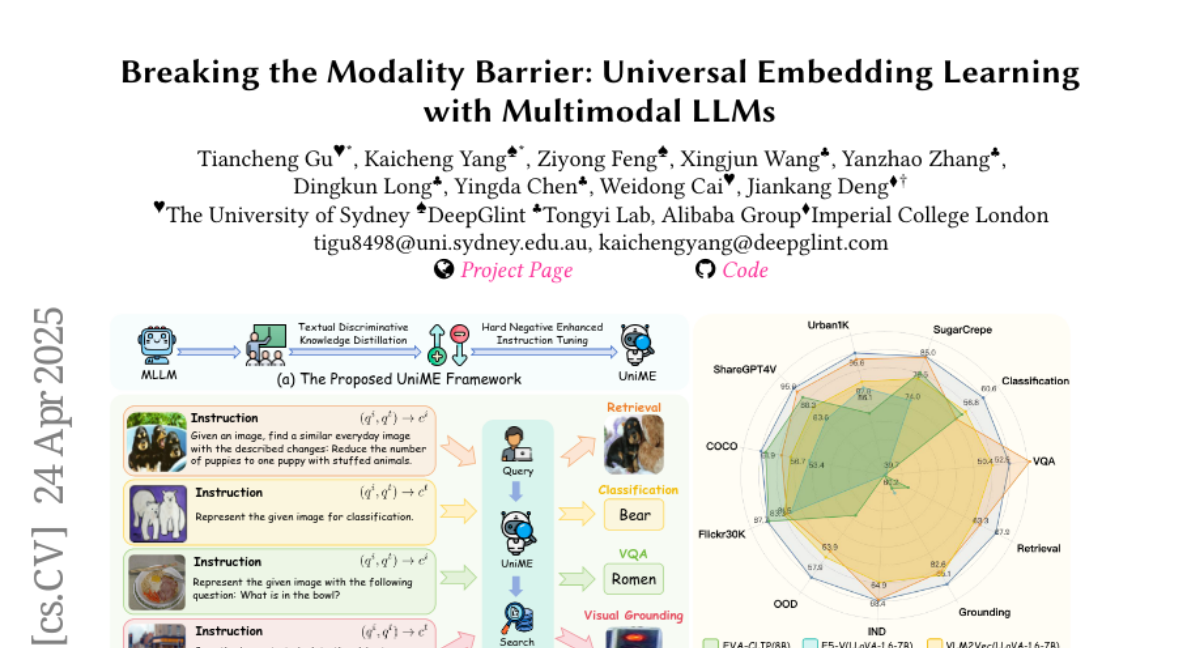
The researchers designed a two-step training process where a strong language model teaches a multimodal model how to create powerful, shared representations—called embeddings—that work across different data types. They also improved the model's learning by making it practice on tough examples where it has to tell apart very similar but incorrect options, which helps it get even better at understanding instructions and details.
Why it matters?
This matters because it opens the door for smarter AI systems that can handle all kinds of information together, making them more useful for things like searching, understanding, and creating content that mixes words, pictures, and sounds.
Abstract
A two-stage framework using Multimodal Large Language Models learns discriminative embeddings for various tasks by distilling knowledge from a powerful LLM and enhancing instruction tuning with hard negatives.