Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Arie Cattan, Alon Jacovi, Alex Fabrikant, Jonathan Herzig, Roee Aharoni, Hannah Rashkin, Dror Marcus, Avinatan Hassidim, Yossi Matias, Idan Szpektor, Avi Caciularu
2024-06-25
Summary
This paper discusses a new method for improving how large language models (LLMs) handle long texts when answering questions. It focuses on using a technique called 'context recycling' to create examples that help the model learn better.
What's the problem?
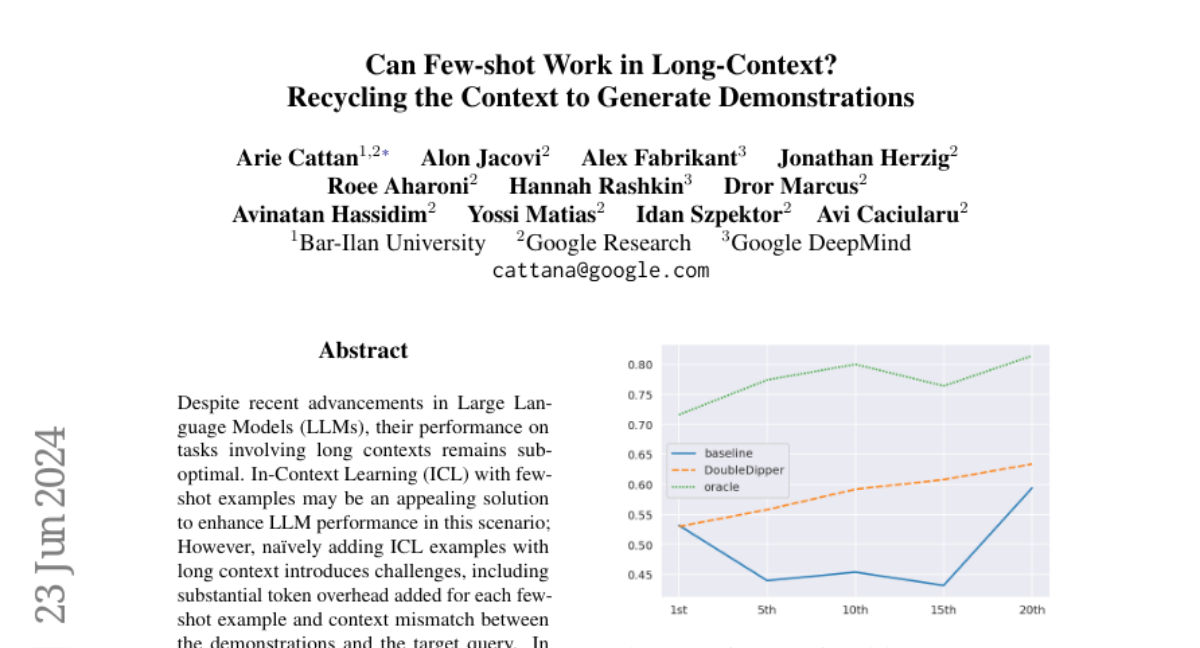
Even though LLMs have improved a lot, they still struggle with tasks that involve long contexts, like long articles or documents. When trying to use few-shot examples (where you give the model a few examples to learn from), it can be difficult because adding too many examples can overwhelm the model and make it harder for it to focus on the relevant information. This leads to poor performance, especially when the answer is located in the middle of the text.
What's the solution?
The authors propose a method called context recycling, where they automatically generate helpful examples from the long input text itself. Instead of adding many separate examples, they create additional question-answer pairs from the same context, ensuring that the model uses relevant information without adding too much extra text. They also guide the model to identify important paragraphs before answering questions, which helps improve its performance. Their approach shows a significant improvement in answering questions correctly, with an average increase of 23% across different models.
Why it matters?
This research is important because it provides a way to enhance how LLMs work with long texts, making them more effective for real-world applications like reading comprehension and information retrieval. By improving the ability of these models to understand and respond to complex queries, it can lead to better user experiences in various fields such as education, customer support, and research.
Abstract
Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements (+23\% on average across models) on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.