Cautious Optimizers: Improving Training with One Line of Code
Kaizhao Liang, Lizhang Chen, Bo Liu, Qiang Liu
2024-11-26
Summary
This paper discusses a new approach called Cautious Optimizers, which improves the training of machine learning models with just one line of code, making existing optimizers faster and more stable.
What's the problem?
Many machine learning models use an optimizer called AdamW for training, but researchers have been looking for ways to make optimizers faster and more reliable. Existing methods often require complex changes or new algorithms, which can be difficult to implement and test.
What's the solution?
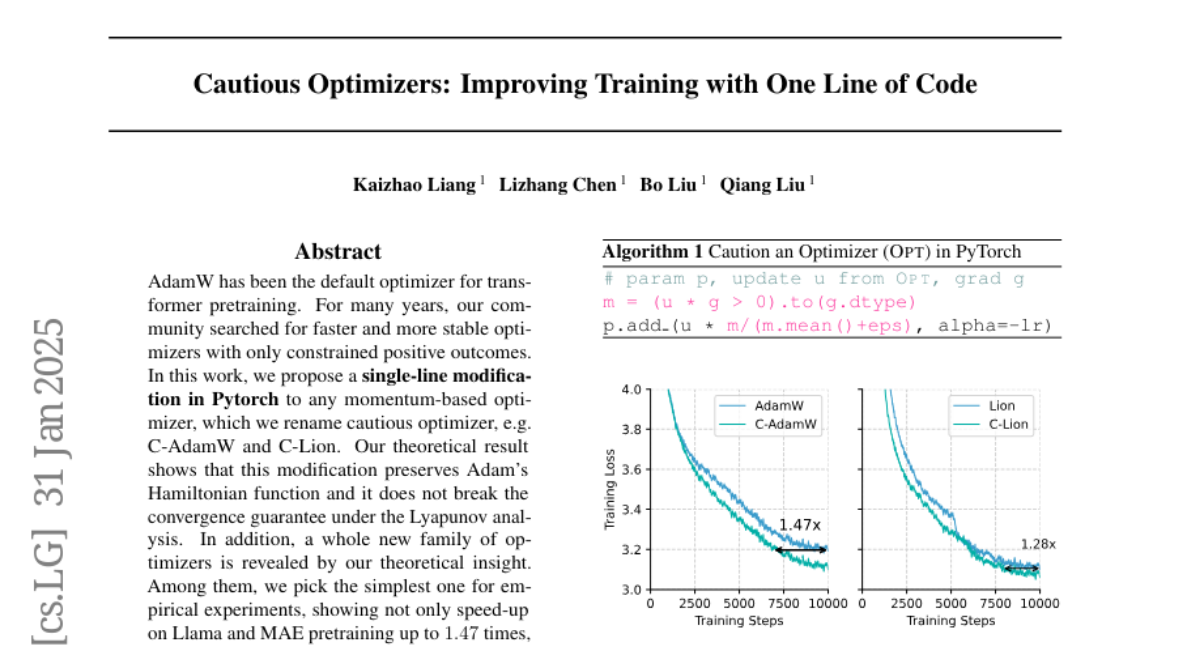
The authors propose a simple modification to any momentum-based optimizer, like AdamW, which they call the Cautious Optimizer. This change preserves important mathematical properties of the optimizer, ensuring that it can still converge correctly during training. They show that this new approach can speed up training times by up to 1.47 times on popular models like Llama and MAE, without sacrificing performance.
Why it matters?
This research is significant because it provides a straightforward way to enhance the efficiency of existing training methods in machine learning. By making it easier for researchers to implement these improvements, Cautious Optimizers could lead to faster and more effective model training across various applications in AI.
Abstract
AdamW has been the default optimizer for transformer pretraining. For many years, our community searches for faster and more stable optimizers with only constraint positive outcomes. In this work, we propose a single-line modification in Pytorch to any momentum-based optimizer, which we rename Cautious Optimizer, e.g. C-AdamW and C-Lion. Our theoretical result shows that this modification preserves Adam's Hamiltonian function and it does not break the convergence guarantee under the Lyapunov analysis. In addition, a whole new family of optimizers is revealed by our theoretical insight. Among them, we pick the simplest one for empirical experiments, showing speed-up on Llama and MAE pretraining up to 1.47times. Code is available at https://github.com/kyleliang919/C-Optim