Characterizing Prompt Compression Methods for Long Context Inference
Siddharth Jha, Lutfi Eren Erdogan, Sehoon Kim, Kurt Keutzer, Amir Gholami
2024-07-15
Summary
This paper discusses the analysis of different methods for compressing prompts in large language models (LLMs) to help them handle long contexts more effectively.
What's the problem?
When LLMs process long inputs, they require a lot of computing power and memory, which can slow down performance and make it harder to understand the information. Existing methods to compress these long prompts have not been thoroughly compared, leading to confusion about which method works best in different situations. This lack of standard analysis has resulted in inconsistent results across various tasks.
What's the solution?
The authors perform a detailed evaluation of several prompt compression techniques, including extractive compression (selecting important parts of the text), summarization-based compression (creating shorter summaries), and token pruning (removing unnecessary words). They found that extractive compression is often the most effective method, allowing for up to 10 times reduction in prompt length with only a small loss in accuracy. In contrast, token pruning methods did not perform as well as previously claimed.
Why it matters?
This research is important because it provides clarity on how to effectively compress prompts for LLMs, which can lead to better performance when dealing with long texts. By understanding which methods work best, developers can create more efficient AI systems that can process information faster and more accurately, ultimately improving user experiences in applications like chatbots and virtual assistants.
Abstract
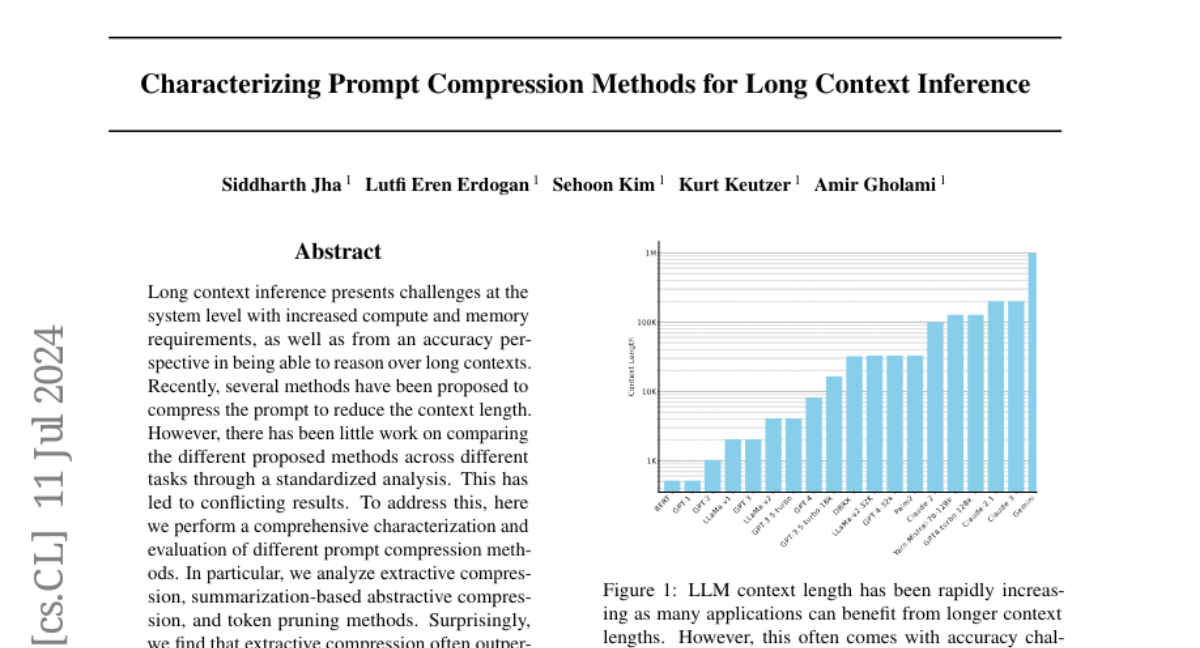
Long context inference presents challenges at the system level with increased compute and memory requirements, as well as from an accuracy perspective in being able to reason over long contexts. Recently, several methods have been proposed to compress the prompt to reduce the context length. However, there has been little work on comparing the different proposed methods across different tasks through a standardized analysis. This has led to conflicting results. To address this, here we perform a comprehensive characterization and evaluation of different prompt compression methods. In particular, we analyze extractive compression, summarization-based abstractive compression, and token pruning methods. Surprisingly, we find that extractive compression often outperforms all the other approaches, and enables up to 10x compression with minimal accuracy degradation. Interestingly, we also find that despite several recent claims, token pruning methods often lag behind extractive compression. We only found marginal improvements on summarization tasks.