Compass Control: Multi Object Orientation Control for Text-to-Image Generation
Rishubh Parihar, Vaibhav Agrawal, Sachidanand VS, R. Venkatesh Babu
2025-04-11
Summary
This paper talks about Compass Control, a new way to make AI-generated images where you can tell the computer exactly which way you want each object in the picture to face, like giving each object its own compass direction. This is especially useful when creating scenes with several objects that need to be positioned and oriented just right.
What's the problem?
The problem is that current text-to-image AI models are good at making images from descriptions, but they struggle when you want to control the exact 3D orientation of multiple objects in one scene. For example, if you want one car facing left and another facing right, most models can't reliably get both directions correct just from the text prompt.
What's the solution?
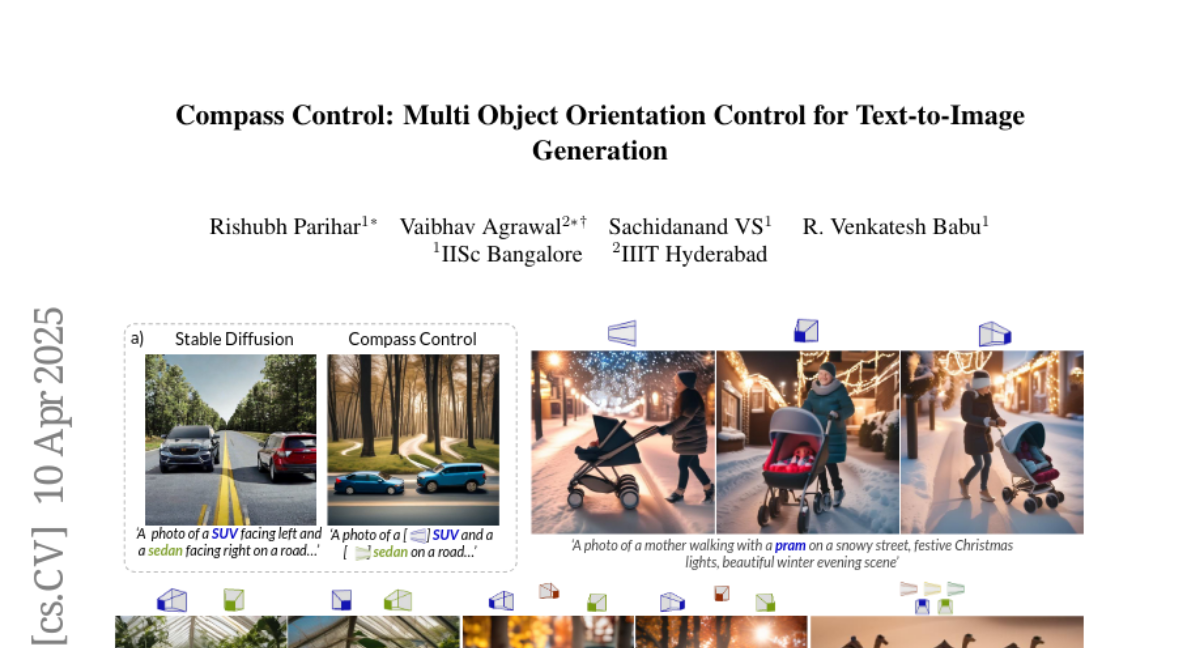
To fix this, the researchers invented a system where each object in the prompt gets a special 'compass token' that encodes its orientation, like an angle or direction. A lightweight encoder turns the desired direction into this token, and the model is trained on lots of computer-generated scenes to learn how to use these tokens. They also added a method that makes sure each compass token only affects its own object, so the directions don't get mixed up. This lets the model generate images where each object faces exactly the way you want, even for new objects or more complicated scenes.
Why it matters?
This work matters because it gives artists, designers, and anyone using AI image generators much more control over how their scenes look, especially when accuracy is important. It also pushes the technology forward by making it possible to create more realistic and customized images with less trial and error.
Abstract
Existing approaches for controlling text-to-image diffusion models, while powerful, do not allow for explicit 3D object-centric control, such as precise control of object orientation. In this work, we address the problem of multi-object orientation control in text-to-image diffusion models. This enables the generation of diverse multi-object scenes with precise orientation control for each object. The key idea is to condition the diffusion model with a set of orientation-aware compass tokens, one for each object, along with text tokens. A light-weight encoder network predicts these compass tokens taking object orientation as the input. The model is trained on a synthetic dataset of procedurally generated scenes, each containing one or two 3D assets on a plain background. However, direct training this framework results in poor orientation control as well as leads to entanglement among objects. To mitigate this, we intervene in the generation process and constrain the cross-attention maps of each compass token to its corresponding object regions. The trained model is able to achieve precise orientation control for a) complex objects not seen during training and b) multi-object scenes with more than two objects, indicating strong generalization capabilities. Further, when combined with personalization methods, our method precisely controls the orientation of the new object in diverse contexts. Our method achieves state-of-the-art orientation control and text alignment, quantified with extensive evaluations and a user study.