CoSTAast: Cost-Sensitive Toolpath Agent for Multi-turn Image Editing
Advait Gupta, NandaKiran Velaga, Dang Nguyen, Tianyi Zhou
2025-03-14
Summary
This paper talks about CoSTA*, a smart AI helper that plans and picks the best tools for editing images in multiple steps, like changing colors or swapping objects, while saving time and computer power.
What's the problem?
Current AI image editors either use too many resources or struggle with complex edits requiring multiple changes, like replacing objects while adjusting colors and text.
What's the solution?
CoSTA* uses a language model to break tasks into smaller steps, then picks the best tools (like object detectors or text editors) and finds the most efficient order using a smart search method that balances quality and cost.
Why it matters?
This makes complex image editing faster and cheaper for tasks like social media content or graphic design, letting users choose between high-quality results or quick edits without needing expensive setups.
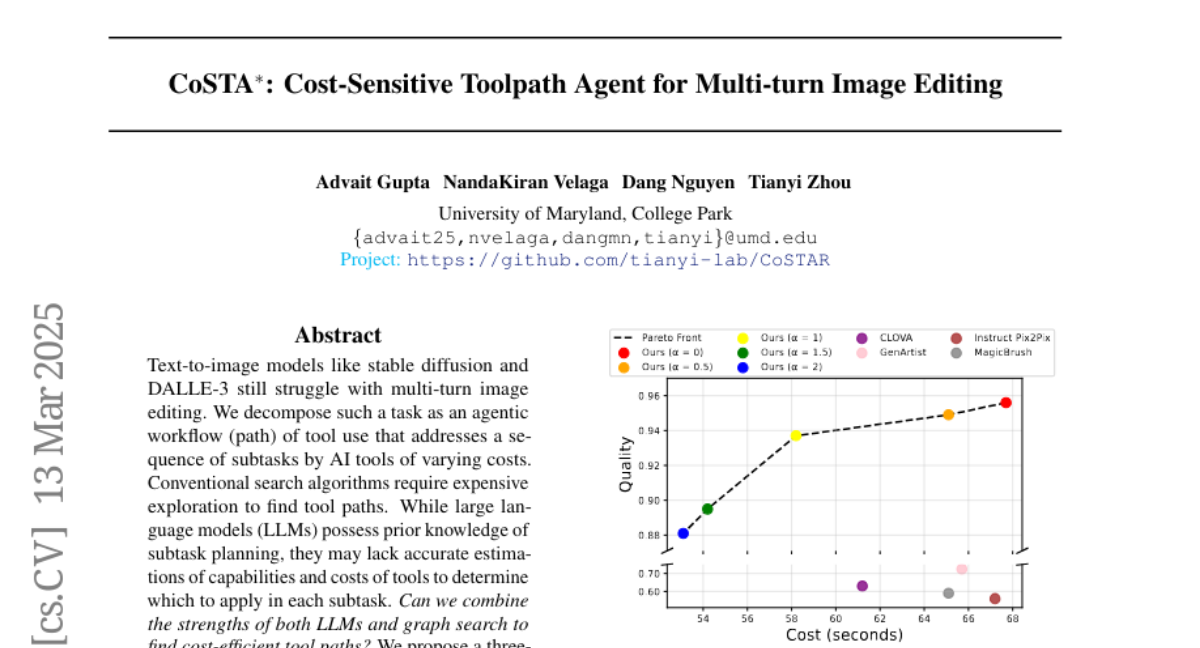
Abstract
Text-to-image models like stable diffusion and DALLE-3 still struggle with multi-turn image editing. We decompose such a task as an agentic workflow (path) of tool use that addresses a sequence of subtasks by AI tools of varying costs. Conventional search algorithms require expensive exploration to find tool paths. While large language models (LLMs) possess prior knowledge of subtask planning, they may lack accurate estimations of capabilities and costs of tools to determine which to apply in each subtask. Can we combine the strengths of both LLMs and graph search to find cost-efficient tool paths? We propose a three-stage approach "CoSTA*" that leverages LLMs to create a subtask tree, which helps prune a graph of AI tools for the given task, and then conducts A* search on the small subgraph to find a tool path. To better balance the total cost and quality, CoSTA* combines both metrics of each tool on every subtask to guide the A* search. Each subtask's output is then evaluated by a vision-language model (VLM), where a failure will trigger an update of the tool's cost and quality on the subtask. Hence, the A* search can recover from failures quickly to explore other paths. Moreover, CoSTA* can automatically switch between modalities across subtasks for a better cost-quality trade-off. We build a novel benchmark of challenging multi-turn image editing, on which CoSTA* outperforms state-of-the-art image-editing models or agents in terms of both cost and quality, and performs versatile trade-offs upon user preference.