DDT: Decoupled Diffusion Transformer
Shuai Wang, Zhi Tian, Weilin Huang, Limin Wang
2025-04-10
Summary
This paper talks about DDT, a new AI image generator that works faster and makes higher quality pictures by separating the jobs of understanding the image’s main idea and adding fine details.
What's the problem?
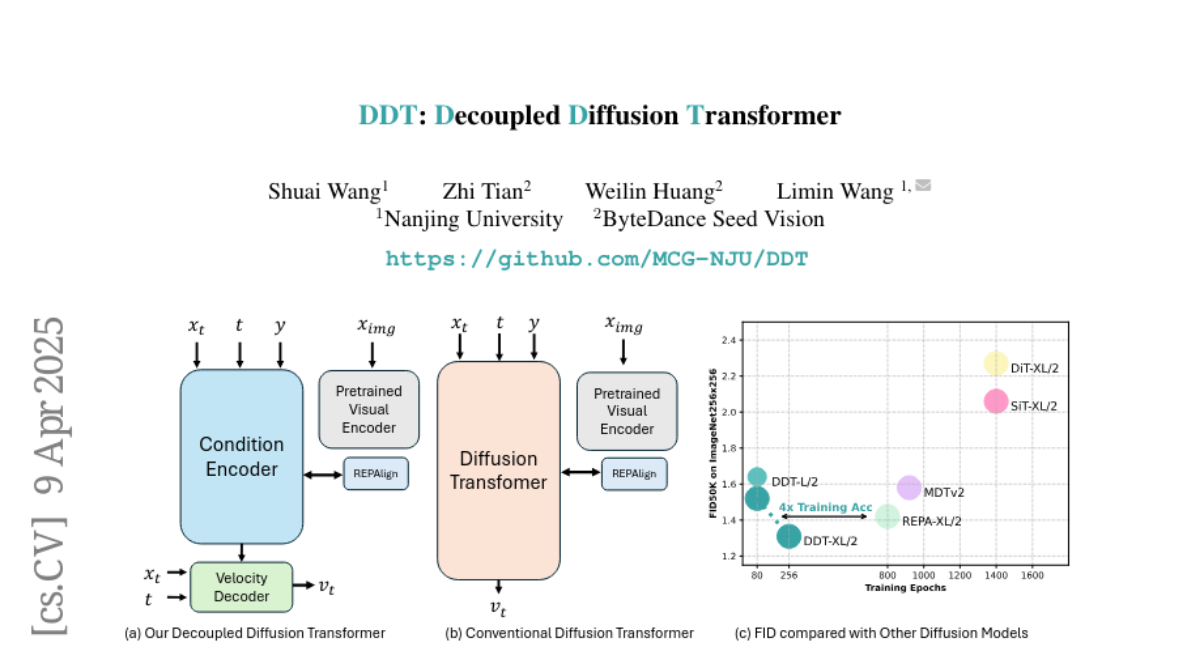
Current AI image generators using diffusion transformers are slow to train and need many steps to make images because they use the same parts of the model to handle both big-picture ideas and tiny details, which causes conflicts.
What's the solution?
DDT splits the work into two parts—a dedicated ‘idea catcher’ that focuses on the image’s overall theme, and a ‘detail painter’ that fills in sharp features—and uses smart tricks to speed up the process without losing quality.
Why it matters?
This makes AI image tools like art generators or design assistants quicker to train and more efficient, producing sharper results for things like digital art, product mockups, or game graphics.
Abstract
Diffusion transformers have demonstrated remarkable generation quality, albeit requiring longer training iterations and numerous inference steps. In each denoising step, diffusion transformers encode the noisy inputs to extract the lower-frequency semantic component and then decode the higher frequency with identical modules. This scheme creates an inherent optimization dilemma: encoding low-frequency semantics necessitates reducing high-frequency components, creating tension between semantic encoding and high-frequency decoding. To resolve this challenge, we propose a new \color{ddtD}ecoupled \color{ddtD}iffusion \color{ddtT}ransformer~(\color{ddtDDT}), with a decoupled design of a dedicated condition encoder for semantic extraction alongside a specialized velocity decoder. Our experiments reveal that a more substantial encoder yields performance improvements as model size increases. For ImageNet 256times256, Our DDT-XL/2 achieves a new state-of-the-art performance of {1.31 FID}~(nearly 4times faster training convergence compared to previous diffusion transformers). For ImageNet 512times512, Our DDT-XL/2 achieves a new state-of-the-art FID of 1.28. Additionally, as a beneficial by-product, our decoupled architecture enhances inference speed by enabling the sharing self-condition between adjacent denoising steps. To minimize performance degradation, we propose a novel statistical dynamic programming approach to identify optimal sharing strategies.