DICEPTION: A Generalist Diffusion Model for Visual Perceptual Tasks
Canyu Zhao, Mingyu Liu, Huanyi Zheng, Muzhi Zhu, Zhiyue Zhao, Hao Chen, Tong He, Chunhua Shen
2025-02-25
Summary
This paper talks about DICEPTION, a new AI model that can perform multiple visual tasks like recognizing objects, estimating depth, and understanding scenes in images, all with a single system.
What's the problem?
Usually, different AI models are needed for different visual tasks, which requires a lot of computing power and training data. This makes it hard to create a single, efficient AI that can handle many visual tasks at once.
What's the solution?
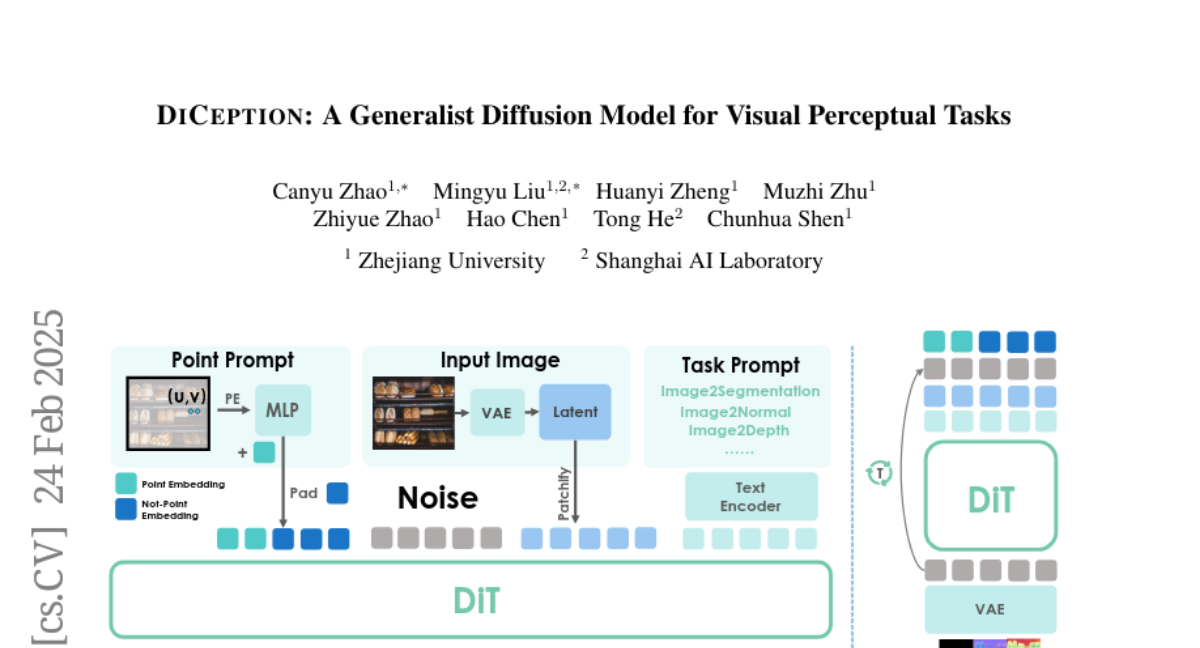
The researchers created DICEPTION by using text-to-image diffusion models that were pre-trained on billions of images. They used a clever trick of encoding different visual tasks using colors, which allowed the model to handle multiple tasks efficiently. DICEPTION can achieve results similar to specialized models while using much less data and computing power.
Why it matters?
This matters because DICEPTION could make AI vision systems more versatile and accessible. It can perform multiple tasks with less data and resources, which could lead to more efficient and capable AI in various applications like robotics, autonomous vehicles, and image analysis tools. The ability to quickly adapt to new tasks with minimal fine-tuning also makes it more flexible for real-world use.
Abstract
Our primary goal here is to create a good, generalist perception model that can tackle multiple tasks, within limits on computational resources and training data. To achieve this, we resort to text-to-image diffusion models pre-trained on billions of images. Our exhaustive evaluation metrics demonstrate that DICEPTION effectively tackles multiple perception tasks, achieving performance on par with state-of-the-art models. We achieve results on par with SAM-vit-h using only 0.06% of their data (e.g., 600K vs. 1B pixel-level annotated images). Inspired by Wang et al., DICEPTION formulates the outputs of various perception tasks using color encoding; and we show that the strategy of assigning random colors to different instances is highly effective in both entity segmentation and semantic segmentation. Unifying various perception tasks as conditional image generation enables us to fully leverage pre-trained text-to-image models. Thus, DICEPTION can be efficiently trained at a cost of orders of magnitude lower, compared to conventional models that were trained from scratch. When adapting our model to other tasks, it only requires fine-tuning on as few as 50 images and 1% of its parameters. DICEPTION provides valuable insights and a more promising solution for visual generalist models.