DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation
Chen Chen, Rui Qian, Wenze Hu, Tsu-Jui Fu, Lezhi Li, Bowen Zhang, Alex Schwing, Wei Liu, Yinfei Yang
2025-03-14
Summary
This paper talks about improving how text-to-image generation models work by studying a specific type of model called Diffusion Transformers (DiTs). It introduces new designs, such as DiT-Air and DiT-Air-Lite, which are smaller but still perform very well.
What's the problem?
Text-to-image generation models are powerful but often require a lot of computing resources and large model sizes. This makes them harder to use efficiently, especially when scaling up for bigger tasks.
What's the solution?
The researchers analyzed different designs of Diffusion Transformers and found ways to make them smaller and more efficient without losing much performance. They introduced new models like DiT-Air, which uses strategies like layer-wise parameter sharing to reduce size while achieving high accuracy.
Why it matters?
This work matters because it shows how to make text-to-image generation models more efficient and accessible. Smaller models can save computing power and make advanced AI tools available to more people and industries.
Abstract
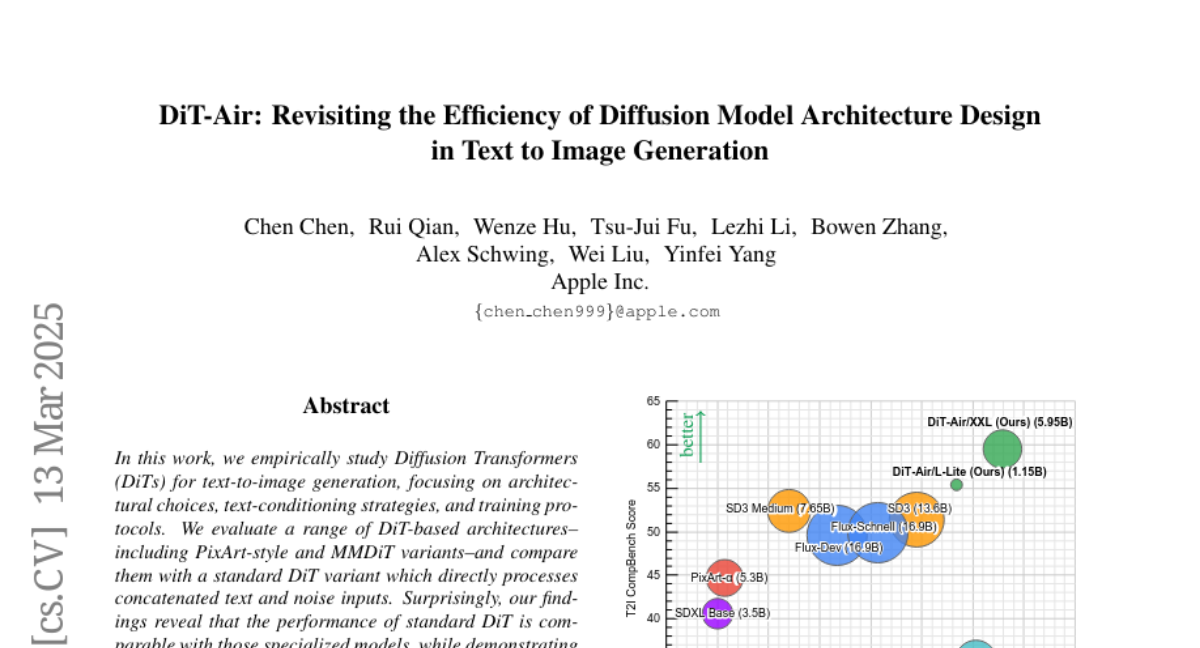
In this work, we empirically study Diffusion Transformers (DiTs) for text-to-image generation, focusing on architectural choices, text-conditioning strategies, and training protocols. We evaluate a range of DiT-based architectures--including PixArt-style and MMDiT variants--and compare them with a standard DiT variant which directly processes concatenated text and noise inputs. Surprisingly, our findings reveal that the performance of standard DiT is comparable with those specialized models, while demonstrating superior parameter-efficiency, especially when scaled up. Leveraging the layer-wise parameter sharing strategy, we achieve a further reduction of 66% in model size compared to an MMDiT architecture, with minimal performance impact. Building on an in-depth analysis of critical components such as text encoders and Variational Auto-Encoders (VAEs), we introduce DiT-Air and DiT-Air-Lite. With supervised and reward fine-tuning, DiT-Air achieves state-of-the-art performance on GenEval and T2I CompBench, while DiT-Air-Lite remains highly competitive, surpassing most existing models despite its compact size.