Does Data Scaling Lead to Visual Compositional Generalization?
Arnas Uselis, Andrea Dittadi, Seong Joon Oh
2025-07-09
Summary
This paper talks about how well vision models, which are AI systems that understand images, can learn to recognize new combinations of objects and features by training on different data. It focuses on whether just having more data helps models generalize better to new combinations or if having more variety in the data matters more.
What's the problem?
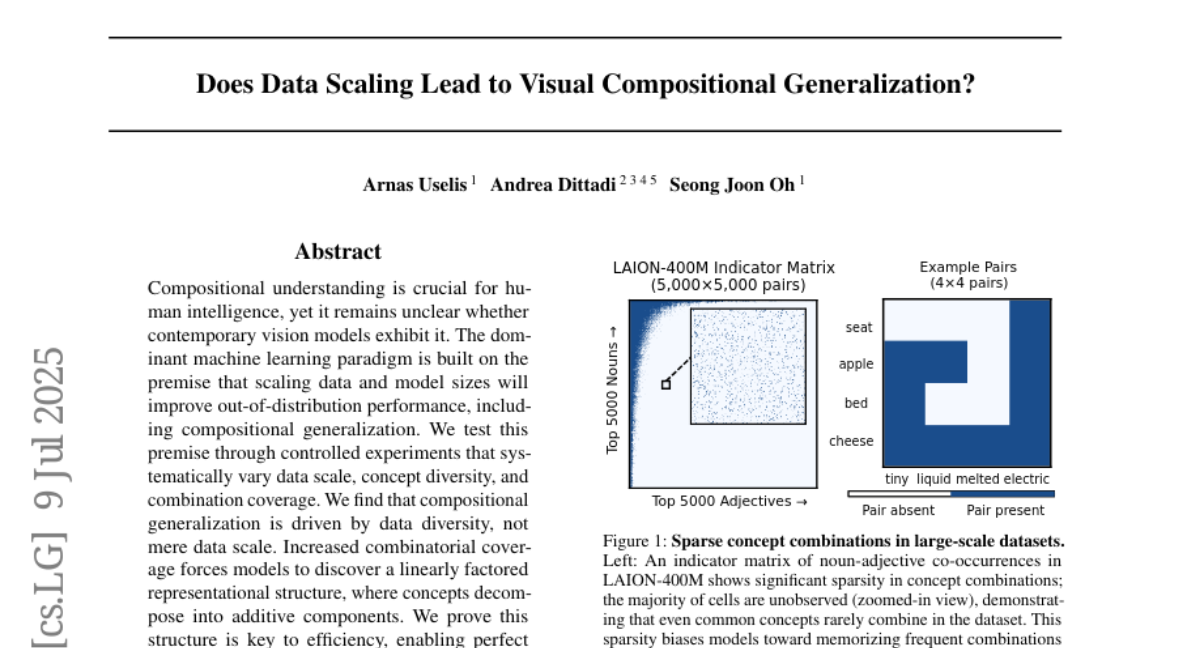
The problem is that AI models often struggle to apply what they learned to new combinations of things they haven’t seen before. People assume that making the training data bigger will fix this, but it’s not clear if size or diversity of data is more important for learning these new combinations.
What's the solution?
The researchers conducted controlled experiments changing the amount of data, variety of concepts, and their combinations in the training sets. They found that diversity, meaning having many different examples and combinations, is what really helps models generalize well, not just having more data. They also showed that when models see diverse combinations, they develop a structure in how they represent features that makes learning new combinations easier.
Why it matters?
This matters because it helps AI developers know how best to train vision models so they can better handle new and complex visual tasks, which is important for applications like robotics, self-driving cars, and image recognition.
Abstract
Compositional generalization in vision models is driven by data diversity rather than scale, and is facilitated by a linearly factored representational structure.