DoraCycle: Domain-Oriented Adaptation of Unified Generative Model in Multimodal Cycles
Rui Zhao, Weijia Mao, Mike Zheng Shou
2025-03-05
Summary
This paper talks about DoraCycle, a new method for adapting AI models that generate images and text to work better in specific areas or styles without needing lots of matched image-text pairs
What's the problem?
Usually, to make AI models good at generating specific types of images or text, you need a lot of examples where images and text are perfectly matched. This is hard to get and takes a lot of time and effort
What's the solution?
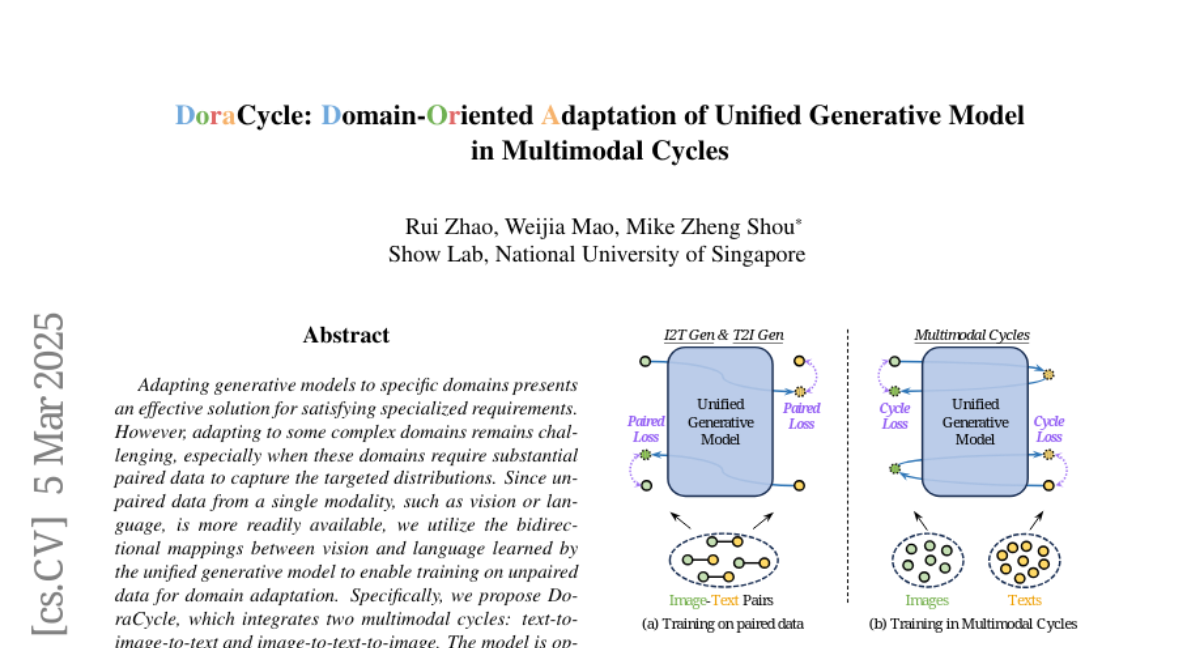
The researchers created DoraCycle, which uses two clever tricks: it turns text into images and back to text, and turns images into text and back to images. This lets the AI learn from unpaired data - separate sets of images and text that don't need to match perfectly. For some tasks, it can learn just from unpaired data, while for others, it needs a small amount of paired data plus a larger amount of unpaired data
Why it matters?
This matters because it makes it much easier and faster to adapt AI models for specific uses. For example, you could quickly teach an AI to generate images in a particular art style or write about specific topics without needing to create huge, perfectly matched datasets. This could lead to more specialized and efficient AI tools for various industries and creative fields
Abstract
Adapting generative models to specific domains presents an effective solution for satisfying specialized requirements. However, adapting to some complex domains remains challenging, especially when these domains require substantial paired data to capture the targeted distributions. Since unpaired data from a single modality, such as vision or language, is more readily available, we utilize the bidirectional mappings between vision and language learned by the unified generative model to enable training on unpaired data for domain adaptation. Specifically, we propose DoraCycle, which integrates two multimodal cycles: text-to-image-to-text and image-to-text-to-image. The model is optimized through cross-entropy loss computed at the cycle endpoints, where both endpoints share the same modality. This facilitates self-evolution of the model without reliance on annotated text-image pairs. Experimental results demonstrate that for tasks independent of paired knowledge, such as stylization, DoraCycle can effectively adapt the unified model using only unpaired data. For tasks involving new paired knowledge, such as specific identities, a combination of a small set of paired image-text examples and larger-scale unpaired data is sufficient for effective domain-oriented adaptation. The code will be released at https://github.com/showlab/DoraCycle.