DoTA-RAG: Dynamic of Thought Aggregation RAG
Saksorn Ruangtanusak, Natthapath Rungseesiripak, Peerawat Rojratchadakorn, Monthol Charattrakool, Natapong Nitarach
2025-06-17
Summary
This paper talks about DoTA-RAG, a new system designed to make searching and generating answers from huge collections of web data faster and more accurate. It uses a smart multi-step process that changes how queries are handled by rewriting them, directing them dynamically to the best parts of the data, and carefully retrieving and ranking results using the best embedding models.
What's the problem?
The problem is that traditional retrieval-augmented generation systems, which help AI models find and use information from large datasets, often become slow and less accurate when dealing with massive and diverse amounts of web data. This makes it hard to get correct answers quickly when the data is very large and complicated.
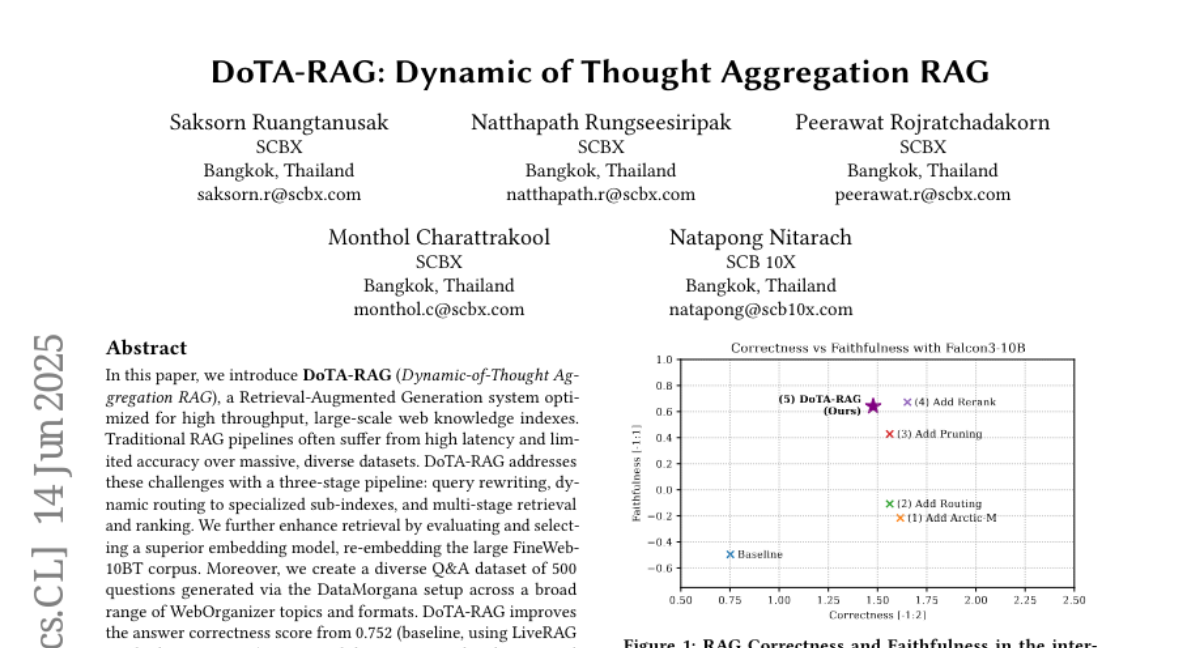
What's the solution?
The solution is DoTA-RAG’s three-stage pipeline that first rewrites the user’s query to improve understanding, then dynamically routes the query to specialized sub-indexes of the data best suited to answer it, and finally uses multiple steps to retrieve and rank the most relevant and accurate information. They also improved the system by choosing a better embedding model to represent the data, which helps in matching queries to answers more effectively.
Why it matters?
This matters because it makes AI systems better at quickly finding accurate information from huge and constantly growing web knowledge sources. This allows practical deployment of AI tools that can handle real-world tasks requiring fast, reliable access to large datasets, improving applications like search engines, question answering, and knowledge retrieval.
Abstract
DoTA-RAG improves retrieval and generation accuracy over massive web datasets using a dynamic routing pipeline and optimized embedding models, achieving high correctness scores while maintaining low latency.