DyMU: Dynamic Merging and Virtual Unmerging for Efficient VLMs
Zhenhailong Wang, Senthil Purushwalkam, Caiming Xiong, Silvio Savarese, Heng Ji, Ran Xu
2025-04-25
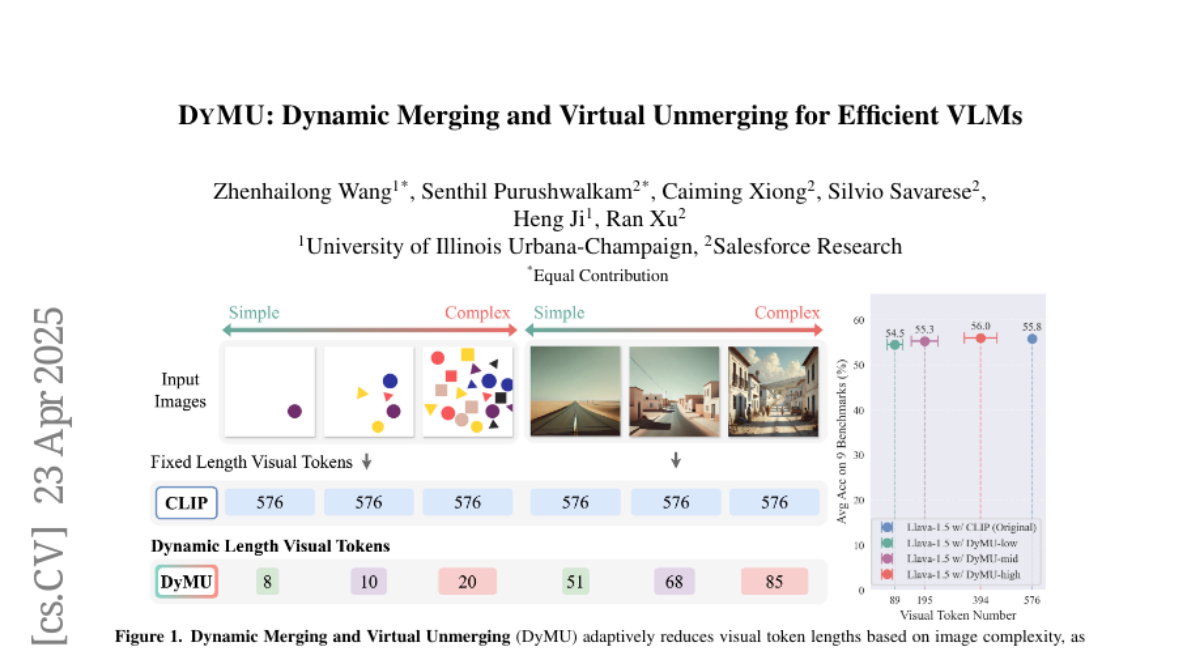
Summary
This paper talks about DyMU, a new technique that helps AI models that work with both images and text run faster and use less computer power, all without needing to retrain them or making their results worse.
What's the problem?
The problem is that vision-language models, which are AIs that understand both pictures and words, can be very slow and require a lot of computer resources because they have to process a huge number of tiny pieces of data, called tokens, at once.
What's the solution?
The researchers created DyMU, which smartly combines these tokens together when possible and then splits them apart again when needed. This dynamic merging and unmerging lets the model handle less data at a time, making it much more efficient, but it still keeps the quality of its answers and results the same.
Why it matters?
This matters because it allows powerful AI models to work faster and on less expensive hardware, making them more accessible and practical for things like smartphones, tablets, and other devices that can't handle heavy computations.
Abstract
DyMU, an efficient, training-free framework, reduces the computational load of vision-language models by dynamically merging and unmerging tokens without performance loss.