Edit Transfer: Learning Image Editing via Vision In-Context Relations
Lan Chen, Qi Mao, Yuchao Gu, Mike Zheng Shou
2025-03-18
Summary
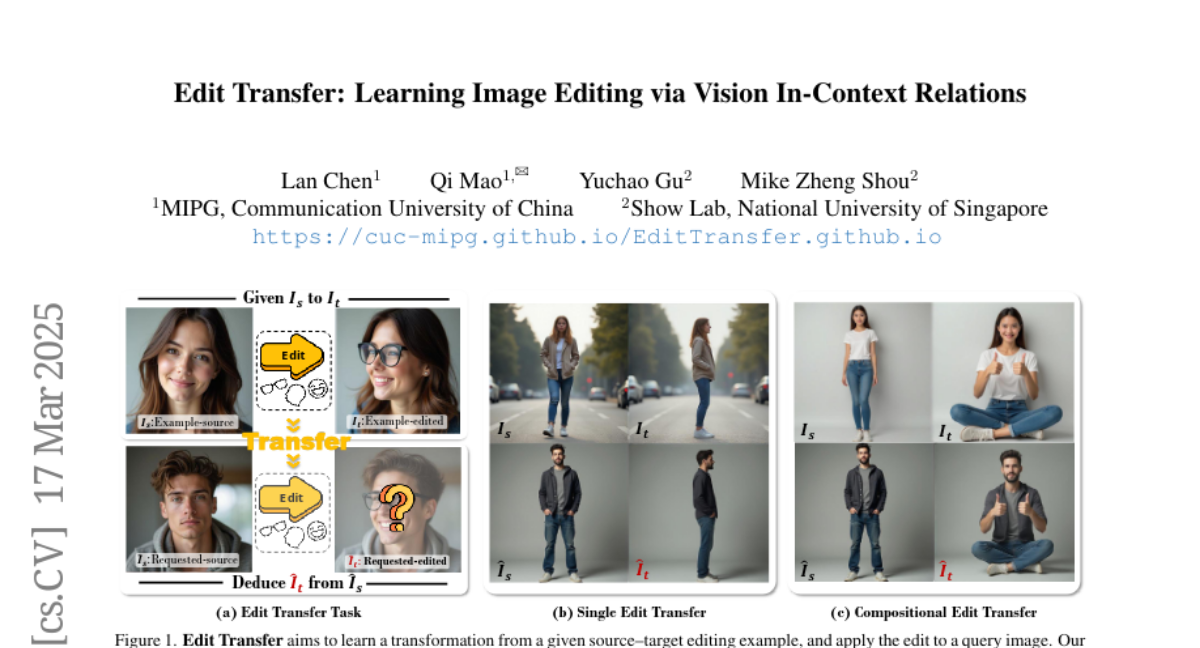
This paper introduces a new method called Edit Transfer for editing images by learning how to transform them from just one example.
What's the problem?
Existing image editing methods have limitations. Text-based methods are good at changing the meaning of images but struggle with precise details like poses. Other methods that use reference images are good at changing the style but not at making significant changes to the image's structure.
What's the solution?
Edit Transfer learns the editing transformation directly from a single source-target image pair. It uses a visual relation in-context learning approach, arranging the example images into a composite and fine-tuning a model to capture complex spatial transformations. This allows the model to apply the learned edit to new images.
Why it matters?
This work matters because it provides a way to edit images with more precision and control, overcoming the limitations of existing methods and requiring very few training examples.
Abstract
We introduce a new setting, Edit Transfer, where a model learns a transformation from just a single source-target example and applies it to a new query image. While text-based methods excel at semantic manipulations through textual prompts, they often struggle with precise geometric details (e.g., poses and viewpoint changes). Reference-based editing, on the other hand, typically focuses on style or appearance and fails at non-rigid transformations. By explicitly learning the editing transformation from a source-target pair, Edit Transfer mitigates the limitations of both text-only and appearance-centric references. Drawing inspiration from in-context learning in large language models, we propose a visual relation in-context learning paradigm, building upon a DiT-based text-to-image model. We arrange the edited example and the query image into a unified four-panel composite, then apply lightweight LoRA fine-tuning to capture complex spatial transformations from minimal examples. Despite using only 42 training samples, Edit Transfer substantially outperforms state-of-the-art TIE and RIE methods on diverse non-rigid scenarios, demonstrating the effectiveness of few-shot visual relation learning.