Factorized Visual Tokenization and Generation
Zechen Bai, Jianxiong Gao, Ziteng Gao, Pichao Wang, Zheng Zhang, Tong He, Mike Zheng Shou
2024-11-26
Summary
This paper introduces Factorized Visual Tokenization and Generation, a new method that improves how images are processed for generation by breaking down large codebooks into smaller, manageable parts.
What's the problem?
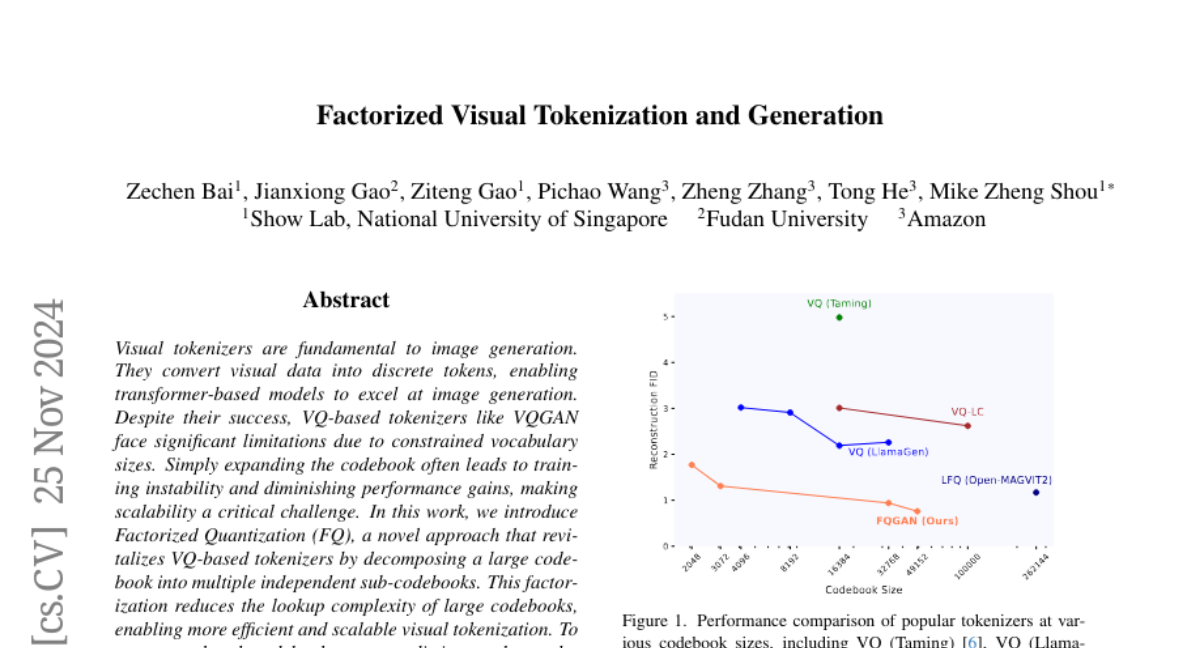
Current visual tokenizers, which convert images into discrete tokens for processing, often struggle with limited vocabulary sizes. When these vocabularies are expanded, it can lead to instability during training and reduced performance. This makes it challenging to scale models effectively for image generation tasks.
What's the solution?
The authors propose a novel approach called Factorized Quantization (FQ), which divides a large codebook into multiple smaller sub-codebooks. This helps reduce the complexity of looking up tokens while allowing the model to capture diverse information. They also introduce a technique called disentanglement regularization to ensure that each sub-codebook learns different aspects of the images without redundancy. By integrating representation learning with pretrained models, their method enhances the richness of the learned representations, leading to better image generation quality.
Why it matters?
This research is significant because it addresses key limitations in existing image generation methods, making them more efficient and effective. By improving how images are tokenized and generated, this work can lead to advancements in various applications such as computer graphics, virtual reality, and artificial intelligence, ultimately enhancing how machines understand and create visual content.
Abstract
Visual tokenizers are fundamental to image generation. They convert visual data into discrete tokens, enabling transformer-based models to excel at image generation. Despite their success, VQ-based tokenizers like VQGAN face significant limitations due to constrained vocabulary sizes. Simply expanding the codebook often leads to training instability and diminishing performance gains, making scalability a critical challenge. In this work, we introduce Factorized Quantization (FQ), a novel approach that revitalizes VQ-based tokenizers by decomposing a large codebook into multiple independent sub-codebooks. This factorization reduces the lookup complexity of large codebooks, enabling more efficient and scalable visual tokenization. To ensure each sub-codebook captures distinct and complementary information, we propose a disentanglement regularization that explicitly reduces redundancy, promoting diversity across the sub-codebooks. Furthermore, we integrate representation learning into the training process, leveraging pretrained vision models like CLIP and DINO to infuse semantic richness into the learned representations. This design ensures our tokenizer captures diverse semantic levels, leading to more expressive and disentangled representations. Experiments show that the proposed FQGAN model substantially improves the reconstruction quality of visual tokenizers, achieving state-of-the-art performance. We further demonstrate that this tokenizer can be effectively adapted into auto-regressive image generation. https://showlab.github.io/FQGAN