FocusLLM: Scaling LLM's Context by Parallel Decoding
Zhenyu Li, Yike Zhang, Tengyu Pan, Yutao Sun, Zhichao Duan, Junjie Fang, Rong Han, Zixuan Wang, Jianyong Wang
2024-08-22
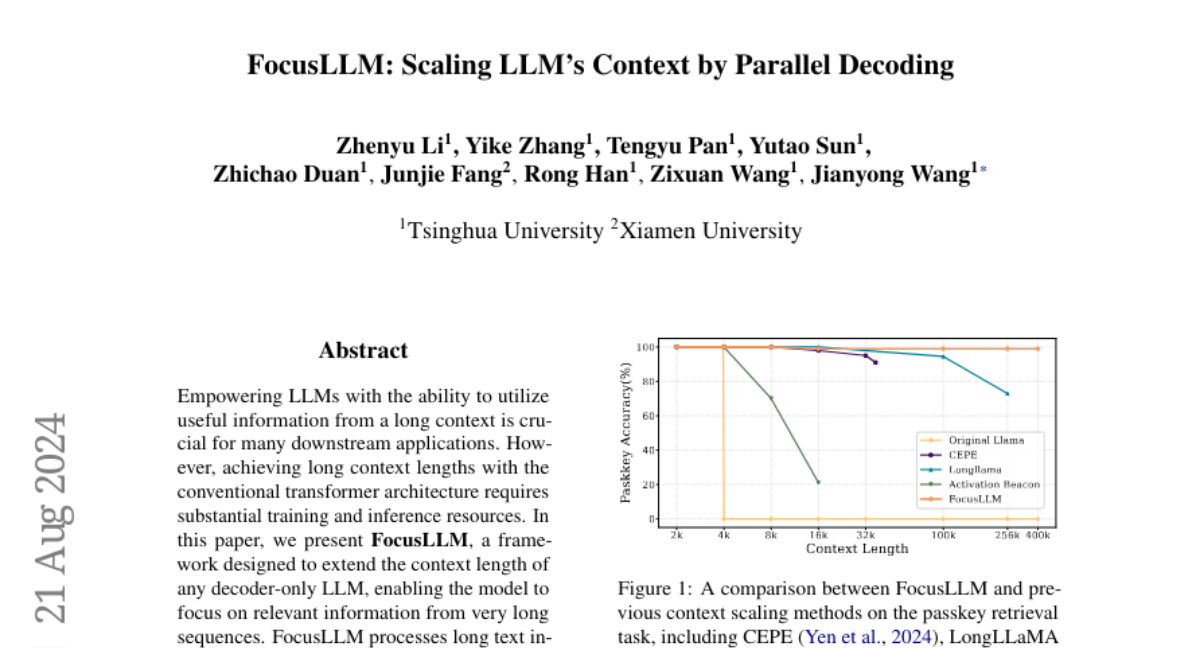
Summary
This paper presents FocusLLM, a new framework that helps large language models (LLMs) handle longer pieces of text more effectively by using a method called parallel decoding.
What's the problem?
Many applications require LLMs to understand and process long texts, but traditional methods struggle with this because they need a lot of resources for training and inference. This makes it hard for these models to focus on important information without getting distracted by irrelevant details.
What's the solution?
FocusLLM addresses this issue by breaking long texts into smaller chunks based on the model's original context length. It then uses a new parallel decoding method to process these chunks while keeping track of relevant information from the entire text. This approach allows the model to efficiently manage long inputs, achieving better performance on tasks that require understanding lengthy content, even up to 400,000 tokens.
Why it matters?
This research is important because it enhances the ability of LLMs to work with long texts, which is crucial for many real-world applications like summarizing articles, answering questions based on lengthy documents, or engaging in detailed conversations. By improving how these models process information, FocusLLM can make AI tools more useful and effective.
Abstract
Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources. In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model's original context length to alleviate the issue of attention distraction. Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism, and ultimately integrates the extracted information into the local context. FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens. Our code is available at https://github.com/leezythu/FocusLLM.