Frequency Dynamic Convolution for Dense Image Prediction
Linwei Chen, Lin Gu, Liang Li, Chenggang Yan, Ying Fu
2025-03-26
Summary
This paper is about improving how computers understand images by making them pay attention to different parts of the image in a smarter way.
What's the problem?
Existing methods for making computers focus on important parts of an image are not very efficient, requiring a lot of computer power and memory.
What's the solution?
The researchers developed a new technique that uses the frequency of different parts of the image to guide the computer's attention, allowing it to focus on the most important details without using a lot of resources.
Why it matters?
This work matters because it can make image recognition more efficient and accurate, which is important for applications like self-driving cars, medical image analysis, and security systems.
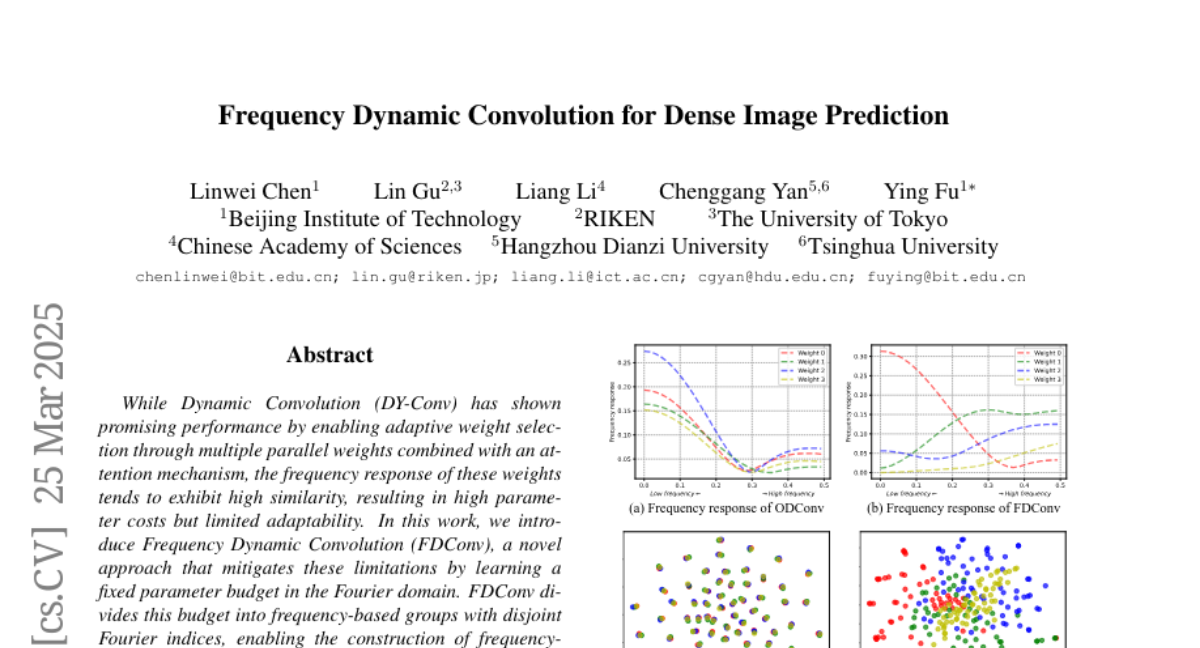
Abstract
While Dynamic Convolution (DY-Conv) has shown promising performance by enabling adaptive weight selection through multiple parallel weights combined with an attention mechanism, the frequency response of these weights tends to exhibit high similarity, resulting in high parameter costs but limited adaptability. In this work, we introduce Frequency Dynamic Convolution (FDConv), a novel approach that mitigates these limitations by learning a fixed parameter budget in the Fourier domain. FDConv divides this budget into frequency-based groups with disjoint Fourier indices, enabling the construction of frequency-diverse weights without increasing the parameter cost. To further enhance adaptability, we propose Kernel Spatial Modulation (KSM) and Frequency Band Modulation (FBM). KSM dynamically adjusts the frequency response of each filter at the spatial level, while FBM decomposes weights into distinct frequency bands in the frequency domain and modulates them dynamically based on local content. Extensive experiments on object detection, segmentation, and classification validate the effectiveness of FDConv. We demonstrate that when applied to ResNet-50, FDConv achieves superior performance with a modest increase of +3.6M parameters, outperforming previous methods that require substantial increases in parameter budgets (e.g., CondConv +90M, KW +76.5M). Moreover, FDConv seamlessly integrates into a variety of architectures, including ConvNeXt, Swin-Transformer, offering a flexible and efficient solution for modern vision tasks. The code is made publicly available at https://github.com/Linwei-Chen/FDConv.