FullDiT: Multi-Task Video Generative Foundation Model with Full Attention
Xuan Ju, Weicai Ye, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Qiang Xu
2025-03-26
Summary
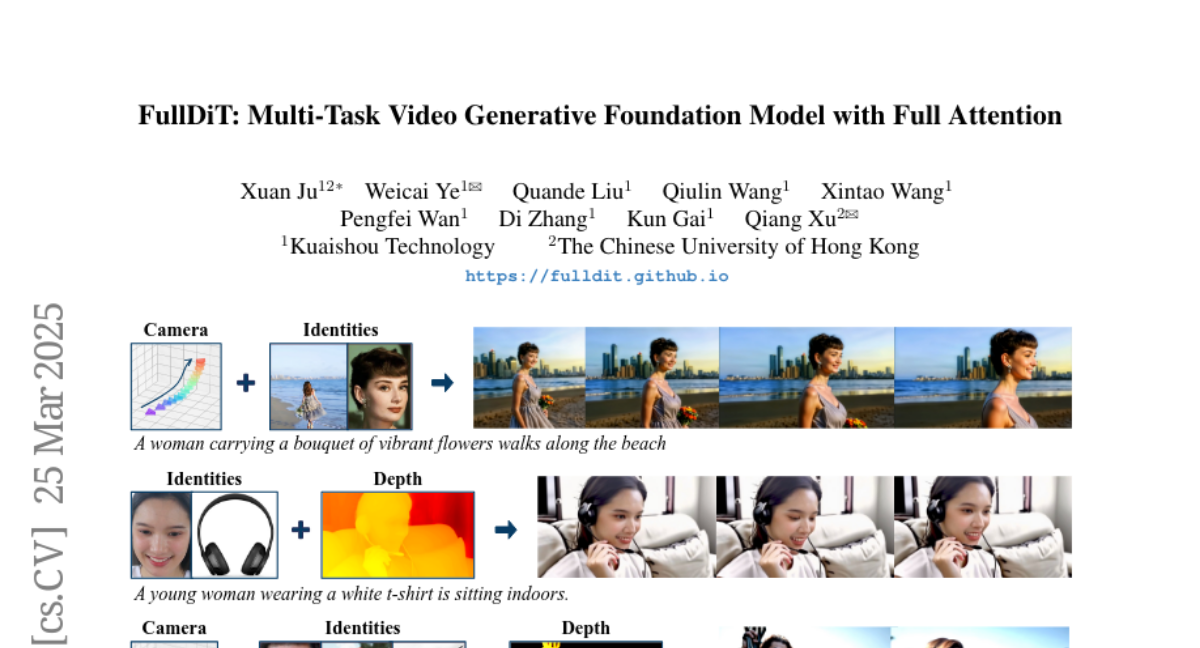
This paper is about creating a single AI model that can generate videos with lots of different controls, like telling it what to show, how to move the camera, and what style to use.
What's the problem?
Existing AI models that generate videos often struggle when you try to control them in multiple ways at once. They might have conflicts between different controls, or they might not be able to handle complex instructions.
What's the solution?
The researchers developed a new AI model called FullDiT that uses a special technique called full attention to combine all the different controls into a single, unified representation. This allows the model to generate videos that follow complex instructions more accurately and efficiently.
Why it matters?
This work matters because it can lead to AI tools that allow people to create more customized and creative videos, which could be useful for things like filmmaking, animation, and visual effects.
Abstract
Current video generative foundation models primarily focus on text-to-video tasks, providing limited control for fine-grained video content creation. Although adapter-based approaches (e.g., ControlNet) enable additional controls with minimal fine-tuning, they encounter challenges when integrating multiple conditions, including: branch conflicts between independently trained adapters, parameter redundancy leading to increased computational cost, and suboptimal performance compared to full fine-tuning. To address these challenges, we introduce FullDiT, a unified foundation model for video generation that seamlessly integrates multiple conditions via unified full-attention mechanisms. By fusing multi-task conditions into a unified sequence representation and leveraging the long-context learning ability of full self-attention to capture condition dynamics, FullDiT reduces parameter overhead, avoids conditions conflict, and shows scalability and emergent ability. We further introduce FullBench for multi-task video generation evaluation. Experiments demonstrate that FullDiT achieves state-of-the-art results, highlighting the efficacy of full-attention in complex multi-task video generation.