Impossible Videos
Zechen Bai, Hai Ci, Mike Zheng Shou
2025-03-19
Summary
This paper introduces a new way to test AI's ability to understand and generate videos that show impossible or unrealistic scenarios.
What's the problem?
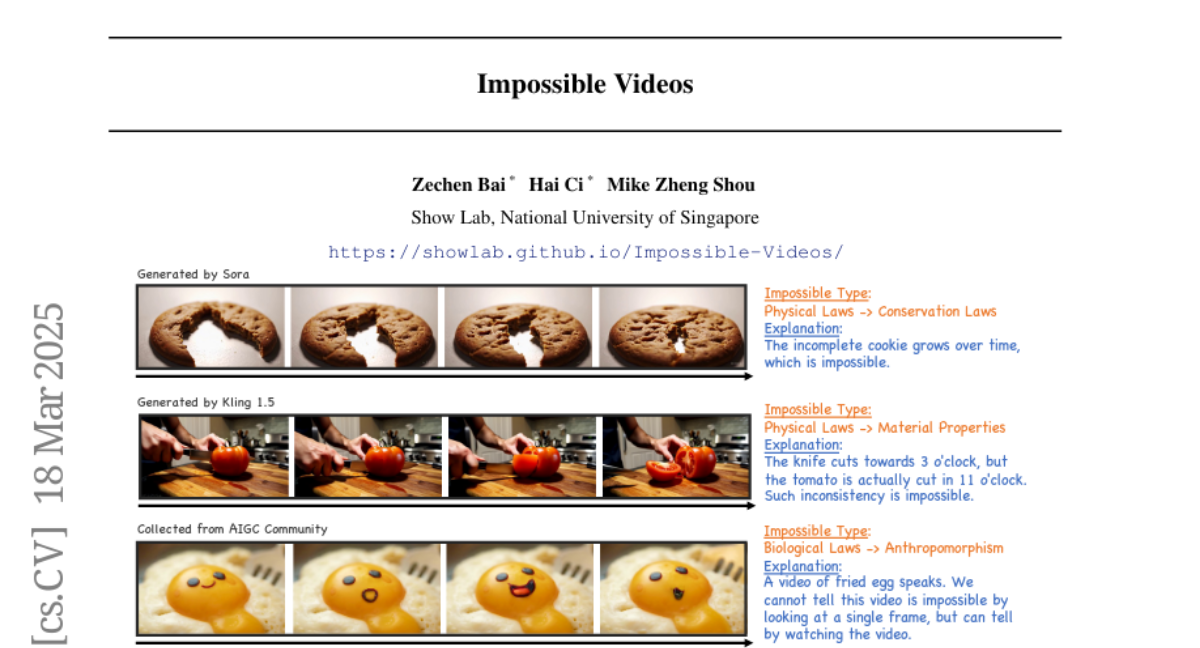
Current AI video models are good at creating realistic videos, but they haven't been challenged to understand or generate videos that break the rules of physics, biology, or society.
What's the solution?
The researchers created a new set of tests called IPV-Bench, which includes videos that show impossible situations. These tests evaluate whether AI models can follow instructions to create these impossible videos and whether they can understand the impossible scenarios shown in the videos.
Why it matters?
This work matters because it pushes AI video models to go beyond simply replicating reality and to develop a deeper understanding of how the world works, even when creating or analyzing things that couldn't exist.
Abstract
Synthetic videos nowadays is widely used to complement data scarcity and diversity of real-world videos. Current synthetic datasets primarily replicate real-world scenarios, leaving impossible, counterfactual and anti-reality video concepts underexplored. This work aims to answer two questions: 1) Can today's video generation models effectively follow prompts to create impossible video content? 2) Are today's video understanding models good enough for understanding impossible videos? To this end, we introduce IPV-Bench, a novel benchmark designed to evaluate and foster progress in video understanding and generation. IPV-Bench is underpinned by a comprehensive taxonomy, encompassing 4 domains, 14 categories. It features diverse scenes that defy physical, biological, geographical, or social laws. Based on the taxonomy, a prompt suite is constructed to evaluate video generation models, challenging their prompt following and creativity capabilities. In addition, a video benchmark is curated to assess Video-LLMs on their ability of understanding impossible videos, which particularly requires reasoning on temporal dynamics and world knowledge. Comprehensive evaluations reveal limitations and insights for future directions of video models, paving the way for next-generation video models.