Improving 2D Feature Representations by 3D-Aware Fine-Tuning
Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, Jan Eric Lenssen
2024-08-01
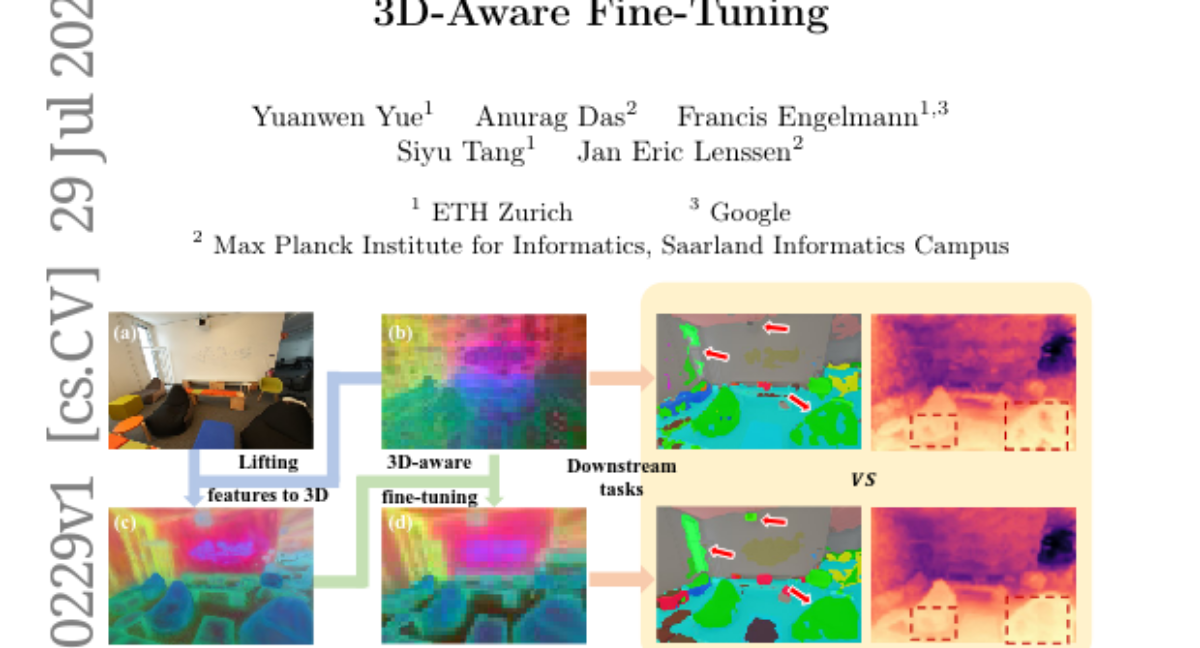
Summary
This paper discusses a new method for improving how computers understand images by incorporating 3D information into 2D visual models. It shows that training on 3D data can enhance the model's ability to recognize and interpret objects in images.
What's the problem?
Most current visual models are trained only on 2D images, which limits their understanding of how objects exist in three dimensions. This lack of 3D awareness can lead to poorer performance when the models are used in real-world applications where depth and spatial relationships matter, such as in robotics or augmented reality.
What's the solution?
The authors propose a method to enhance 2D features by integrating information from 3D data. They create a way to convert 2D features into a 3D representation, allowing the model to learn from both types of data. By fine-tuning the model with these enriched features, they demonstrate that it can perform better on tasks like semantic segmentation (identifying parts of an image) and depth estimation (measuring distance in an image). Their approach shows that even when trained on just one indoor dataset, the improvements can transfer to other datasets, making the model more versatile.
Why it matters?
This research is important because it opens up new possibilities for improving visual recognition systems. By incorporating 3D awareness into training, models can become more accurate and effective in understanding complex scenes. This advancement could lead to better performance in various applications, including self-driving cars, virtual reality, and advanced robotics, ultimately enhancing how machines interact with the world.
Abstract
Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of 3D structure of objects and scenes. In this work, we show that fine-tuning on 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views. Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing. Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models. Project page: https://ywyue.github.io/FiT3D.