Inherently Faithful Attention Maps for Vision Transformers
Ananthu Aniraj, Cassio F. Dantas, Dino Ienco, Diego Marcos
2025-06-16
Summary
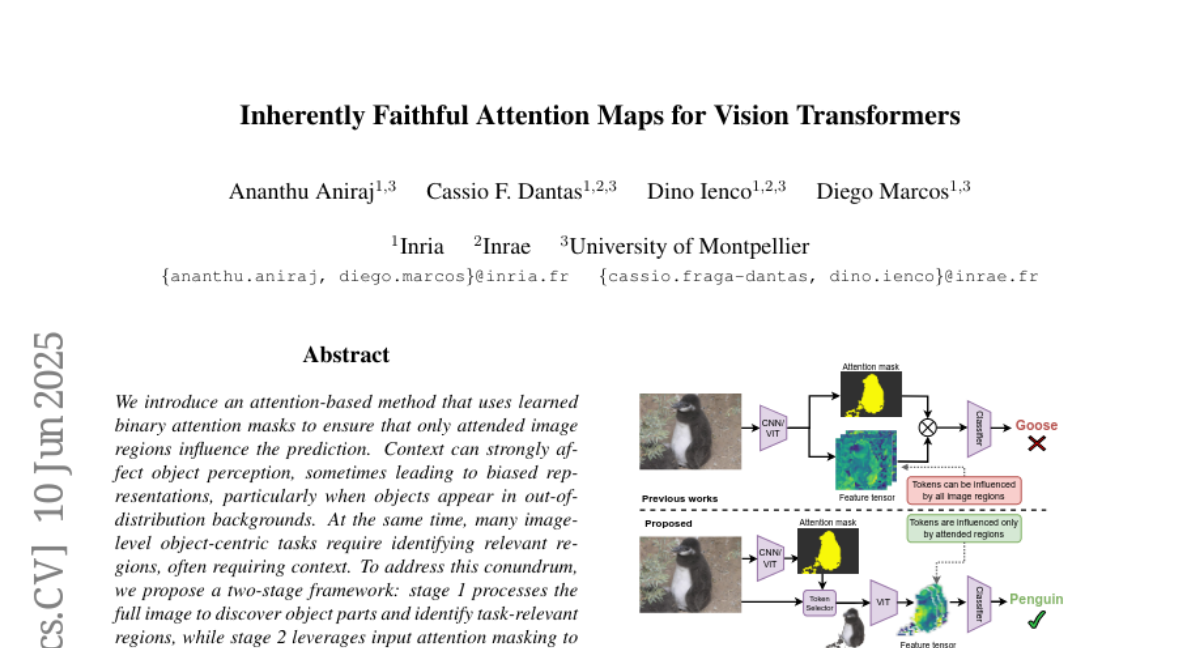
This paper talks about a new attention method for vision transformers, which are AI models that analyze images. The method uses special learned binary masks to help the model focus on the important parts of an image while ignoring irrelevant or misleading details. This makes the model better at seeing and understanding objects correctly.
What's the problem?
The problem is that vision transformers sometimes pay attention to the wrong parts of an image, like noise or background details, which makes their object perception less reliable and can lead to mistakes. Existing attention methods don’t always clearly separate useful information from distractions, hurting the model’s performance and robustness.
What's the solution?
The solution was to create a way to learn binary masks that act as filters during the attention process, allowing the model to focus only on truly relevant image regions. By combining these masks with the attention maps in a vision transformer, the model becomes more faithful to important features and less affected by noise or irrelevant data, improving its accuracy and stability without extra complicated training.
Why it matters?
This matters because improving how vision transformers focus on important image parts helps AI systems see the world more clearly and make better decisions when recognizing objects. This enhancement makes AI models more trustworthy and effective in applications like self-driving cars, medical imaging, and security, where understanding images accurately is crucial.
Abstract
An attention-based method using learned binary masks improves robustness in object perception by focusing on relevant image regions while filtering out spurious information.