Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level
Jie Liu, Zhanhui Zhou, Jiaheng Liu, Xingyuan Bu, Chao Yang, Han-Sen Zhong, Wanli Ouyang
2024-06-21
Summary
This paper discusses a new technique called Iterative Length-Regularized Direct Preference Optimization (iLR-DPO) that improves the performance of smaller language models to match that of larger models like GPT-4.
What's the problem?
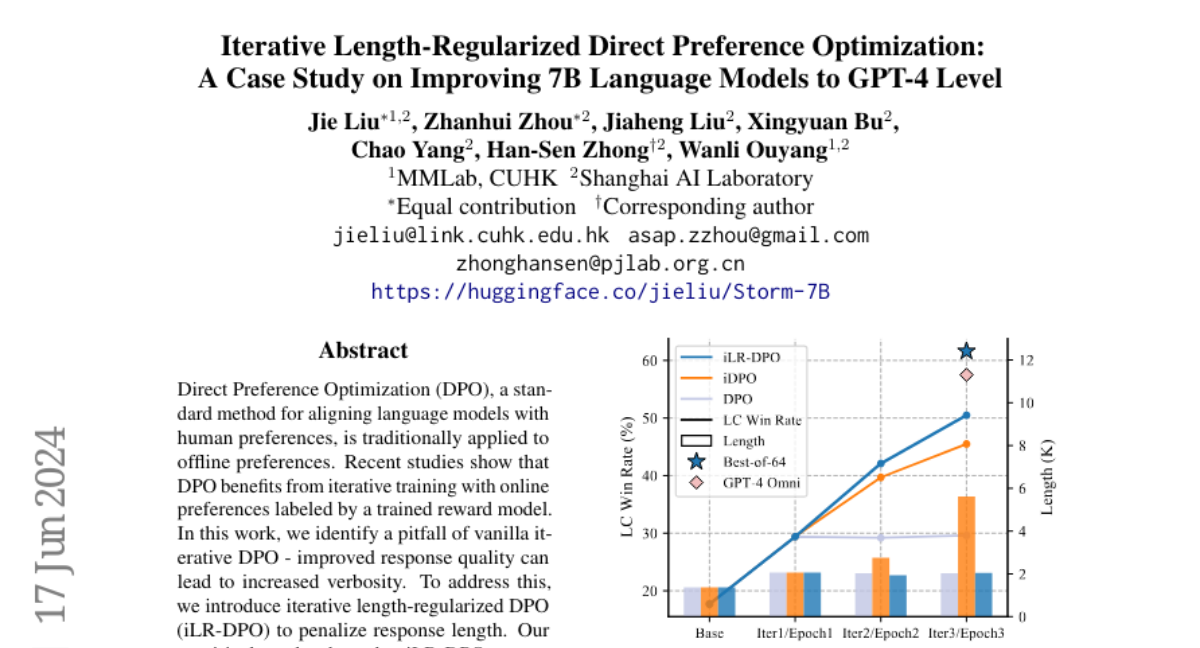
Language models often need to be aligned with human preferences to produce better responses. The traditional method for doing this, called Direct Preference Optimization (DPO), usually works with past data and can lead to a problem where the model generates longer, unnecessary responses instead of concise answers. This verbosity can make the model less effective and harder to use.
What's the solution?
The researchers introduced iLR-DPO, which adds a penalty for longer responses during the training process. This means that while the model learns to improve its answers based on human preferences, it is also encouraged to keep its responses shorter and more relevant. Their experiments showed that this approach allows a 7-billion parameter model to perform similarly to GPT-4 without becoming overly verbose. They tested this model on various benchmarks and found it achieved a 50.5% win rate against GPT-4 in terms of response quality.
Why it matters?
This research is important because it provides a way to enhance smaller language models, making them more competitive with larger ones without requiring massive increases in computing power. By improving how these models respond, we can create more efficient AI tools that are easier for people to interact with, ultimately leading to better user experiences in applications like chatbots, virtual assistants, and more.
Abstract
Direct Preference Optimization (DPO), a standard method for aligning language models with human preferences, is traditionally applied to offline preferences. Recent studies show that DPO benefits from iterative training with online preferences labeled by a trained reward model. In this work, we identify a pitfall of vanilla iterative DPO - improved response quality can lead to increased verbosity. To address this, we introduce iterative length-regularized DPO (iLR-DPO) to penalize response length. Our empirical results show that iLR-DPO can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. Specifically, our 7B model achieves a 50.5% length-controlled win rate against GPT-4 Preview on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard. These results demonstrate the effectiveness of iterative DPO in aligning language models with human feedback.