Kolmogorov-Arnold Attention: Is Learnable Attention Better For Vision Transformers?
Subhajit Maity, Killian Hitsman, Xin Li, Aritra Dutta
2025-03-17
Summary
This collection of papers explores various advancements and challenges in AI, spanning areas like image and video generation, multimodal understanding, robotics, and safety.
What's the problem?
The problems addressed include improving the efficiency and quality of AI-generated content, enhancing the reasoning abilities of AI models, mitigating biases and safety risks, and enabling AI to better interact with the real world.
What's the solution?
The solutions involve developing new models, training techniques, benchmarks, and evaluation methods. These include innovations in diffusion models, transformers, reinforcement learning, and multimodal learning. Specific solutions focus on improving image compression (PerCoV2), generating consistent videos (CINEMA, Long Context Tuning), enabling robots to navigate and manipulate objects (UniGoal, adversarial data collection), and mitigating toxicity in online discussions (Silent Is Not Actually Silent).
Why it matters?
These advancements are important because they push the boundaries of AI capabilities, making AI more powerful, reliable, and beneficial for various applications. They also address critical challenges related to safety, fairness, and transparency, ensuring that AI is developed and deployed responsibly.
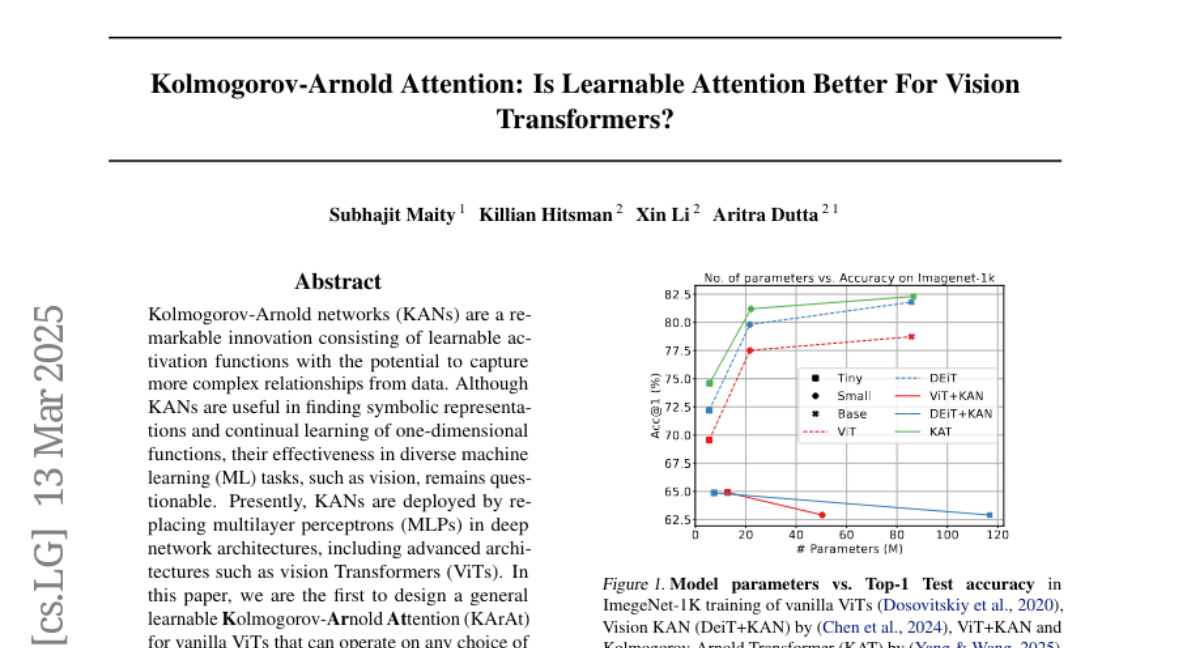
Abstract
Kolmogorov-Arnold networks (KANs) are a remarkable innovation consisting of learnable activation functions with the potential to capture more complex relationships from data. Although KANs are useful in finding symbolic representations and continual learning of one-dimensional functions, their effectiveness in diverse machine learning (ML) tasks, such as vision, remains questionable. Presently, KANs are deployed by replacing multilayer perceptrons (MLPs) in deep network architectures, including advanced architectures such as vision Transformers (ViTs). In this paper, we are the first to design a general learnable Kolmogorov-Arnold Attention (KArAt) for vanilla ViTs that can operate on any choice of basis. However, the computing and memory costs of training them motivated us to propose a more modular version, and we designed particular learnable attention, called Fourier-KArAt. Fourier-KArAt and its variants either outperform their ViT counterparts or show comparable performance on CIFAR-10, CIFAR-100, and ImageNet-1K datasets. We dissect these architectures' performance and generalization capacity by analyzing their loss landscapes, weight distributions, optimizer path, attention visualization, and spectral behavior, and contrast them with vanilla ViTs. The goal of this paper is not to produce parameter- and compute-efficient attention, but to encourage the community to explore KANs in conjunction with more advanced architectures that require a careful understanding of learnable activations. Our open-source code and implementation details are available on: https://subhajitmaity.me/KArAt