Learning 3D Representations from Procedural 3D Programs
Xuweiyi Chen, Zezhou Cheng
2024-11-27
Summary
This paper discusses a new way for computers to learn about 3D objects by using programs that create 3D shapes automatically. This method helps overcome challenges in obtaining labeled 3D data, which is often difficult and expensive.
What's the problem?
Learning about 3D objects is challenging because creating labeled 3D data requires specialized equipment and expertise. Unlike 2D images, which are easy to find and use, 3D models are harder to come by, making it difficult for computers to learn from them. This situation can limit the development of effective machine learning systems for tasks involving 3D representations.
What's the solution?
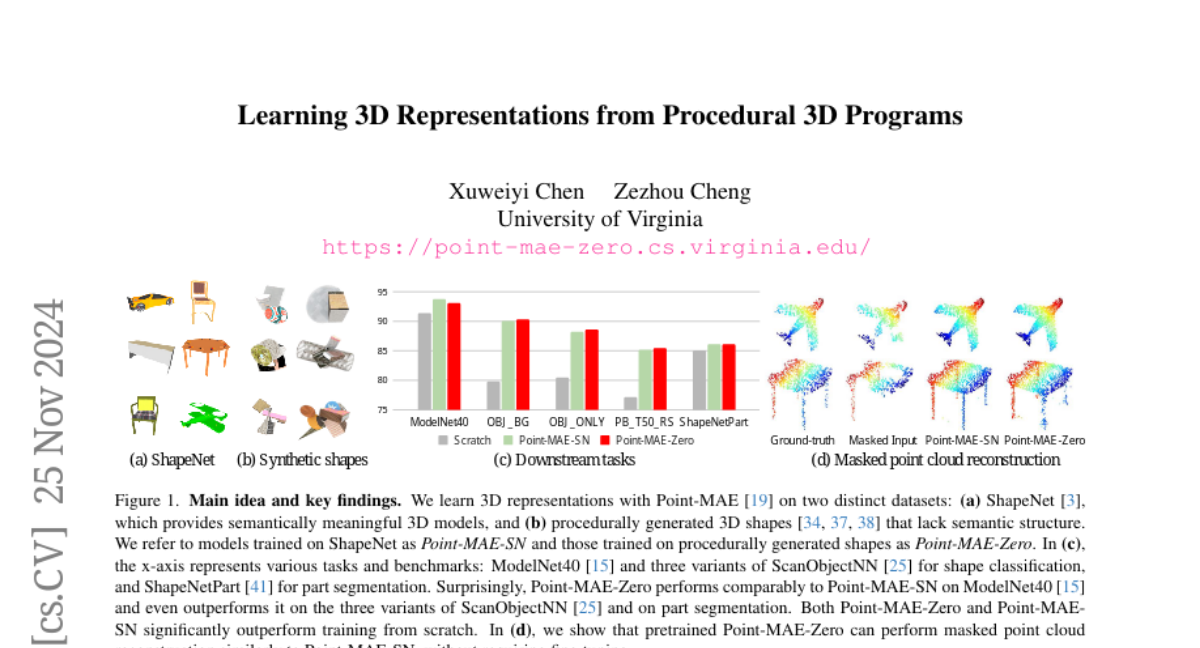
The authors propose a method that uses procedural 3D programs to automatically generate a large variety of 3D shapes using simple building blocks. By training on these generated shapes, the computer can learn useful representations of 3D objects without needing labeled data. The results show that these representations perform as well as those learned from real, recognizable 3D models in various tasks, such as classifying shapes and segmenting parts.
Why it matters?
This research is important because it provides a scalable solution for teaching computers about 3D objects without the need for expensive scanning equipment or extensive labeling efforts. It opens up new possibilities for using machine learning in fields like robotics, gaming, and virtual reality, where understanding 3D shapes is crucial.
Abstract
Self-supervised learning has emerged as a promising approach for acquiring transferable 3D representations from unlabeled 3D point clouds. Unlike 2D images, which are widely accessible, acquiring 3D assets requires specialized expertise or professional 3D scanning equipment, making it difficult to scale and raising copyright concerns. To address these challenges, we propose learning 3D representations from procedural 3D programs that automatically generate 3D shapes using simple primitives and augmentations. Remarkably, despite lacking semantic content, the 3D representations learned from this synthesized dataset perform on par with state-of-the-art representations learned from semantically recognizable 3D models (e.g., airplanes) across various downstream 3D tasks, including shape classification, part segmentation, and masked point cloud completion. Our analysis further suggests that current self-supervised learning methods primarily capture geometric structures rather than high-level semantics.