LiteSearch: Efficacious Tree Search for LLM
Ante Wang, Linfeng Song, Ye Tian, Baolin Peng, Dian Yu, Haitao Mi, Jinsong Su, Dong Yu
2024-07-02
Summary
This paper talks about LiteSearch, a new algorithm designed to improve how large language models (LLMs) solve complex mathematical problems. It focuses on making the search process for solutions more efficient and less resource-intensive.
What's the problem?
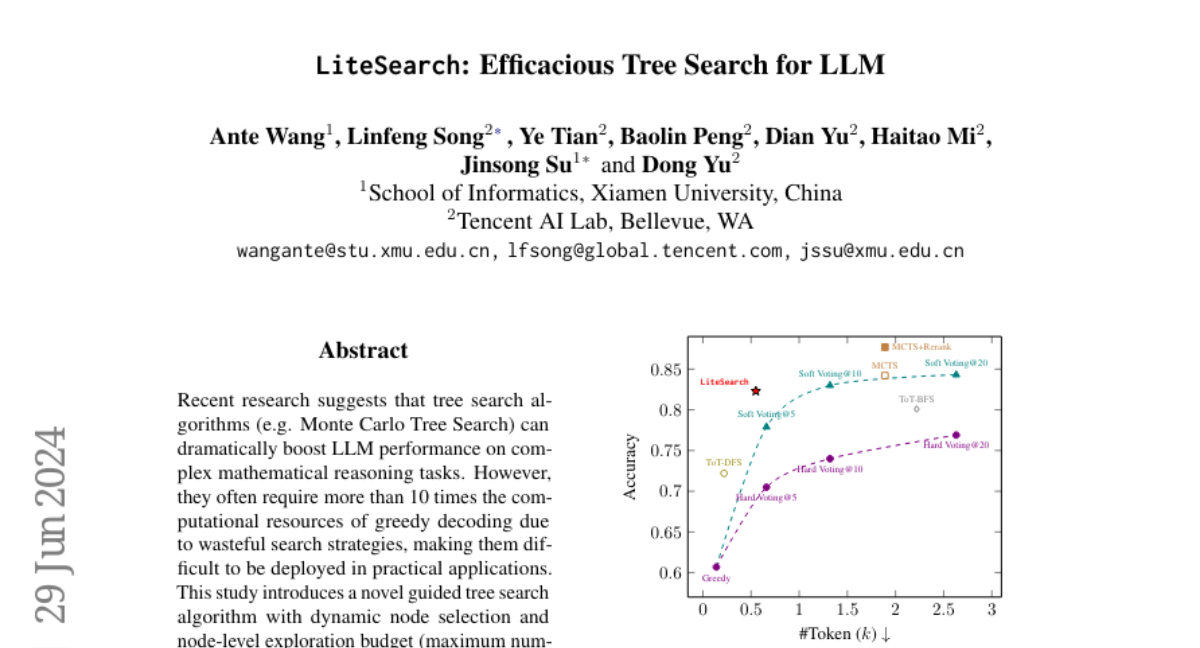
Tree search algorithms, like Monte Carlo Tree Search, can greatly enhance the performance of LLMs on challenging tasks, but they often require a lot of computational power—more than ten times what simpler methods need. This makes them impractical for many real-world applications, as they can be too slow and costly to use.
What's the solution?
To address this issue, the authors developed LiteSearch, which is a guided tree search algorithm that dynamically selects which parts of the search tree to explore. It calculates a budget for how many options (or 'children') to consider at each step, allowing it to focus on the most promising paths without wasting resources. The algorithm uses past search progress and guidance from a value network to make better decisions about which nodes to expand. This method was tested on datasets like GSM8K and TabMWP, showing that it performs well while using significantly fewer resources than traditional methods.
Why it matters?
This research is important because it makes it possible for LLMs to solve complex problems more efficiently. By reducing the computational costs associated with tree search algorithms, LiteSearch can help integrate advanced reasoning capabilities into AI systems in practical ways. This could lead to improvements in various applications, such as education, robotics, and any field that relies on complex decision-making.
Abstract
Recent research suggests that tree search algorithms (e.g. Monte Carlo Tree Search) can dramatically boost LLM performance on complex mathematical reasoning tasks. However, they often require more than 10 times the computational resources of greedy decoding due to wasteful search strategies, making them difficult to be deployed in practical applications. This study introduces a novel guided tree search algorithm with dynamic node selection and node-level exploration budget (maximum number of children) calculation to tackle this issue. By considering the search progress towards the final answer (history) and the guidance from a value network (future) trained without any step-wise annotations, our algorithm iteratively selects the most promising tree node before expanding it within the boundaries of the allocated computational budget. Experiments conducted on the GSM8K and TabMWP datasets demonstrate that our approach not only offers competitive performance but also enjoys significantly lower computational costs compared to baseline methods.