LLaMAX: Scaling Linguistic Horizons of LLM by Enhancing Translation Capabilities Beyond 100 Languages
Yinquan Lu, Wenhao Zhu, Lei Li, Yu Qiao, Fei Yuan
2024-07-09
Summary
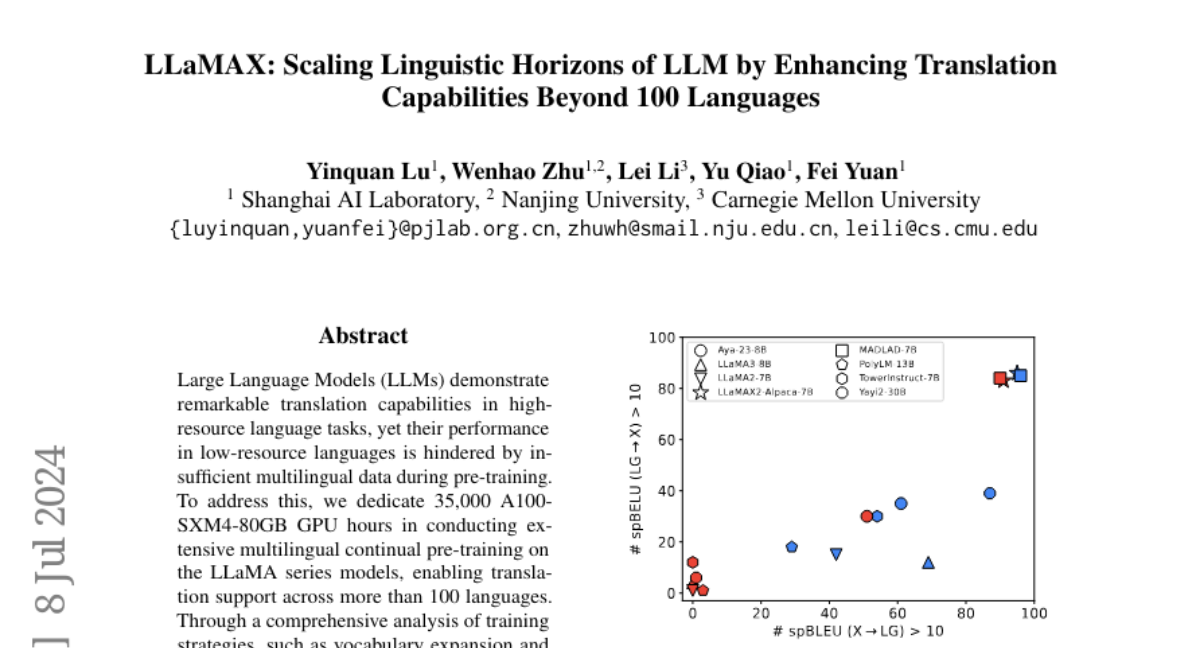
This paper talks about LLaMAX, a new language model designed to improve translation capabilities for over 100 languages, especially focusing on languages that don't have a lot of available training data.
What's the problem?
The main problem is that while large language models (LLMs) are great at translating popular languages, they struggle with low-resource languages because there isn't enough data to train them effectively. This limits their ability to provide accurate translations in many languages spoken around the world.
What's the solution?
To solve this issue, the authors dedicated a significant amount of computing power (35,000 hours on powerful GPUs) to conduct extensive training on the LLaMA series models. They used various strategies like expanding the vocabulary and augmenting data to develop LLaMAX. This model not only improves translation performance by over 10 points compared to existing models but also maintains its ability to generalize well across different tasks and languages.
Why it matters?
This research is important because it enhances the ability of AI systems to understand and translate a wider range of languages, including those that are often overlooked. By improving translation capabilities, LLaMAX can help bridge communication gaps in diverse communities and make information more accessible globally, which is crucial in our interconnected world.
Abstract
Large Language Models~(LLMs) demonstrate remarkable translation capabilities in high-resource language tasks, yet their performance in low-resource languages is hindered by insufficient multilingual data during pre-training. To address this, we dedicate 35,000 A100-SXM4-80GB GPU hours in conducting extensive multilingual continual pre-training on the LLaMA series models, enabling translation support across more than 100 languages. Through a comprehensive analysis of training strategies, such as vocabulary expansion and data augmentation, we develop LLaMAX. Remarkably, without sacrificing its generalization ability, LLaMAX achieves significantly higher translation performance compared to existing open-source LLMs~(by more than 10 spBLEU points) and performs on-par with specialized translation model~(M2M-100-12B) on the Flores-101 benchmark. Extensive experiments indicate that LLaMAX can serve as a robust multilingual foundation model. The code~\url{https://github.com/CONE-MT/LLaMAX/.} and models~\url{https://huggingface.co/LLaMAX/.} are publicly available.