Long-Video Audio Synthesis with Multi-Agent Collaboration
Yehang Zhang, Xinli Xu, Xiaojie Xu, Li Liu, Yingcong Chen
2025-03-18
Summary
This set of research papers covers a wide range of topics in artificial intelligence, focusing on improving AI's ability to understand and generate images, videos, audio, and text, as well as enabling AI to interact with the world through robotics.
What's the problem?
The papers address challenges like making AI-generated content more realistic and consistent, improving AI's reasoning and problem-solving skills, enabling AI to work with limited data or in complex environments, and ensuring AI systems are robust, fair, and safe.
What's the solution?
The solutions proposed involve developing new AI models, training techniques, benchmarks for evaluation, and methods for combining different AI capabilities. These include improvements to diffusion models for generating images and videos, new ways to train language models, methods for robotic control, and techniques for ensuring AI systems are reliable and trustworthy.
Why it matters?
This research is important because it pushes the boundaries of what AI can do, making AI more capable and applicable to a wider range of real-world problems. It also addresses important ethical considerations, helping to ensure that AI is developed and used responsibly for the benefit of society.
Abstract
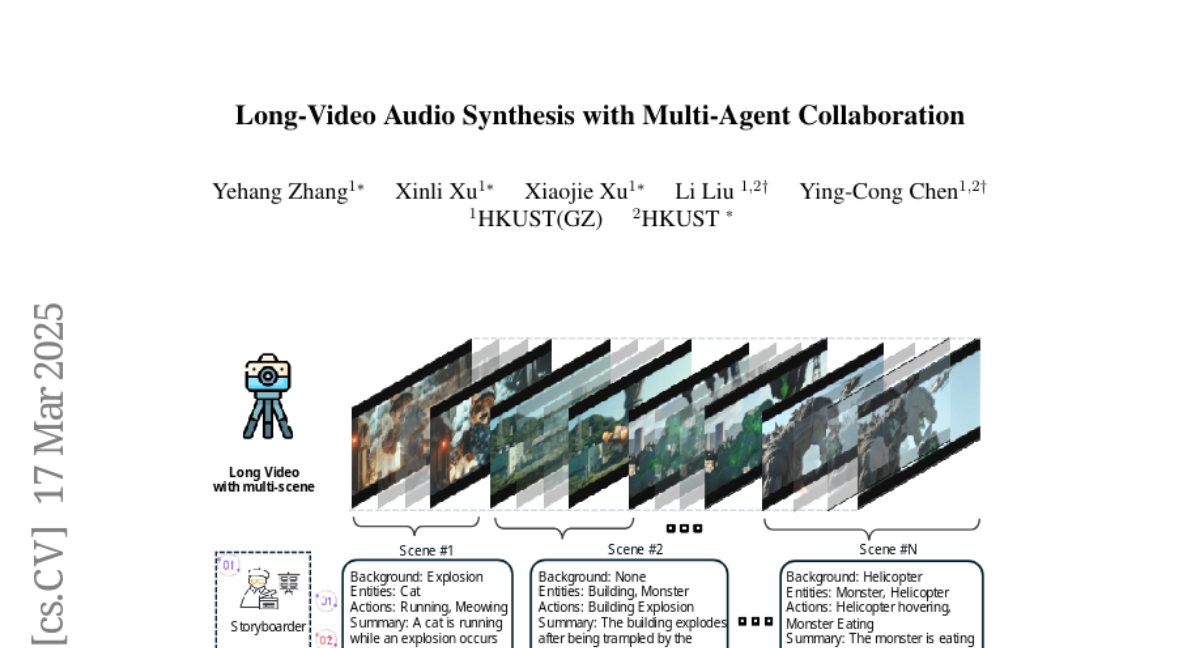
Video-to-audio synthesis, which generates synchronized audio for visual content, critically enhances viewer immersion and narrative coherence in film and interactive media. However, video-to-audio dubbing for long-form content remains an unsolved challenge due to dynamic semantic shifts, temporal misalignment, and the absence of dedicated datasets. While existing methods excel in short videos, they falter in long scenarios (e.g., movies) due to fragmented synthesis and inadequate cross-scene consistency. We propose LVAS-Agent, a novel multi-agent framework that emulates professional dubbing workflows through collaborative role specialization. Our approach decomposes long-video synthesis into four steps including scene segmentation, script generation, sound design and audio synthesis. Central innovations include a discussion-correction mechanism for scene/script refinement and a generation-retrieval loop for temporal-semantic alignment. To enable systematic evaluation, we introduce LVAS-Bench, the first benchmark with 207 professionally curated long videos spanning diverse scenarios. Experiments demonstrate superior audio-visual alignment over baseline methods. Project page: https://lvas-agent.github.io