Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Liu, Bingbing Liu, Ying-Cong Chen
2024-09-27
Summary
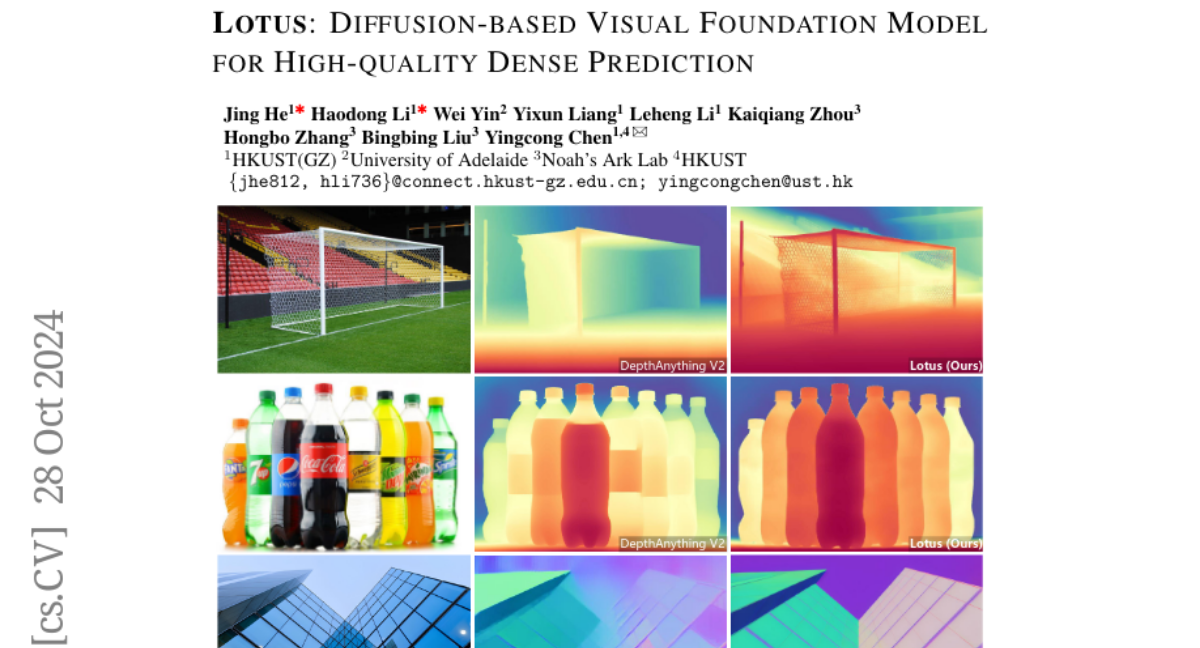
This paper talks about Lotus, a new diffusion-based model designed to improve how computers understand and predict detailed information from images, specifically for tasks that require precise pixel-level predictions like depth estimation.
What's the problem?
Many existing models that use diffusion processes for image generation are not well-suited for dense prediction tasks, which need very accurate and detailed outputs. Traditional methods often predict noise instead of directly predicting what the image should look like, leading to inaccuracies and inefficiencies. Additionally, these models typically require complex multi-step processes that slow down performance.
What's the solution?
Lotus addresses these issues by changing the way the model is trained. Instead of learning to predict noise, it directly predicts annotations (the actual details needed for tasks like depth estimation). The model also simplifies the diffusion process into a single step, making it much faster and easier to optimize. Furthermore, Lotus includes a special technique called 'detail preserver' that helps maintain fine details in the predictions, ensuring high accuracy without needing more training data or larger models.
Why it matters?
This research is important because it significantly enhances the capabilities of AI in understanding and interpreting images. By achieving state-of-the-art performance in tasks like depth and normal estimation without requiring extensive training data, Lotus opens up new possibilities for applications in fields such as robotics, autonomous vehicles, and augmented reality, where accurate spatial understanding is crucial.
Abstract
Leveraging the visual priors of pre-trained text-to-image diffusion models offers a promising solution to enhance zero-shot generalization in dense prediction tasks. However, existing methods often uncritically use the original diffusion formulation, which may not be optimal due to the fundamental differences between dense prediction and image generation. In this paper, we provide a systemic analysis of the diffusion formulation for the dense prediction, focusing on both quality and efficiency. And we find that the original parameterization type for image generation, which learns to predict noise, is harmful for dense prediction; the multi-step noising/denoising diffusion process is also unnecessary and challenging to optimize. Based on these insights, we introduce Lotus, a diffusion-based visual foundation model with a simple yet effective adaptation protocol for dense prediction. Specifically, Lotus is trained to directly predict annotations instead of noise, thereby avoiding harmful variance. We also reformulate the diffusion process into a single-step procedure, simplifying optimization and significantly boosting inference speed. Additionally, we introduce a novel tuning strategy called detail preserver, which achieves more accurate and fine-grained predictions. Without scaling up the training data or model capacity, Lotus achieves SoTA performance in zero-shot depth and normal estimation across various datasets. It also significantly enhances efficiency, being hundreds of times faster than most existing diffusion-based methods.