MagicComp: Training-free Dual-Phase Refinement for Compositional Video Generation
Hongyu Zhang, Yufan Deng, Shenghai Yuan, Peng Jin, Zesen Cheng, Yian Zhao, Chang Liu, Jie Chen
2025-03-25
Summary
This paper is about improving how AI creates videos from text, especially when the text describes multiple things and how they interact.
What's the problem?
Current AI video generators struggle to accurately show different objects in a video, their relationships to each other, and how they interact.
What's the solution?
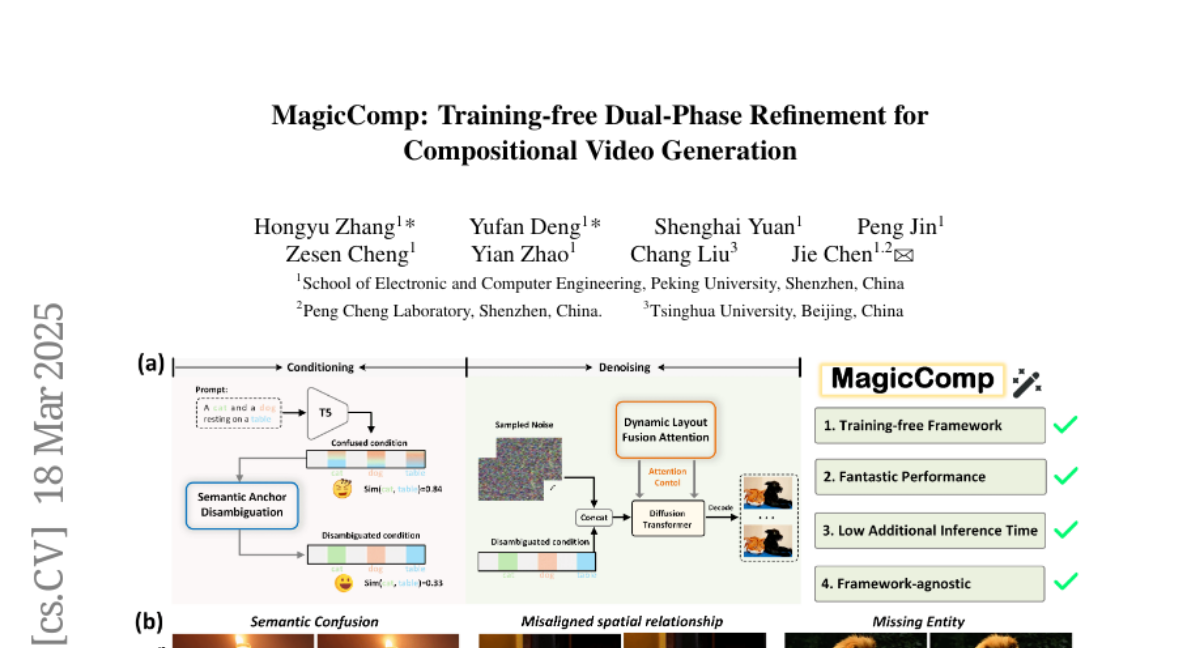
The researchers developed a new method called MagicComp that refines the video creation process in two stages: first, it clarifies the meaning of the text, and second, it makes sure the objects are placed correctly in the video and interact realistically.
Why it matters?
This work matters because it can lead to AI video generators that are better at creating complex and realistic videos from text descriptions.
Abstract
Text-to-video (T2V) generation has made significant strides with diffusion models. However, existing methods still struggle with accurately binding attributes, determining spatial relationships, and capturing complex action interactions between multiple subjects. To address these limitations, we propose MagicComp, a training-free method that enhances compositional T2V generation through dual-phase refinement. Specifically, (1) During the Conditioning Stage: We introduce the Semantic Anchor Disambiguation to reinforces subject-specific semantics and resolve inter-subject ambiguity by progressively injecting the directional vectors of semantic anchors into original text embedding; (2) During the Denoising Stage: We propose Dynamic Layout Fusion Attention, which integrates grounding priors and model-adaptive spatial perception to flexibly bind subjects to their spatiotemporal regions through masked attention modulation. Furthermore, MagicComp is a model-agnostic and versatile approach, which can be seamlessly integrated into existing T2V architectures. Extensive experiments on T2V-CompBench and VBench demonstrate that MagicComp outperforms state-of-the-art methods, highlighting its potential for applications such as complex prompt-based and trajectory-controllable video generation. Project page: https://hong-yu-zhang.github.io/MagicComp-Page/.