Modulated Intervention Preference Optimization (MIPO): Keep the Easy, Refine the Difficult
Cheolhun Jang
2024-09-30
Summary
This paper introduces Modulated Intervention Preference Optimization (MIPO), a new method designed to improve how models learn preferences by adjusting how much they rely on a reference model based on how well it aligns with the given data.
What's the problem?
In preference optimization, existing methods often use a well-trained reference model to guide the learning process. However, if this reference model isn't well-aligned with the data, it can actually hinder the model's ability to learn effectively. This creates a challenge in training models that need to adapt significantly from their initial state.
What's the solution?
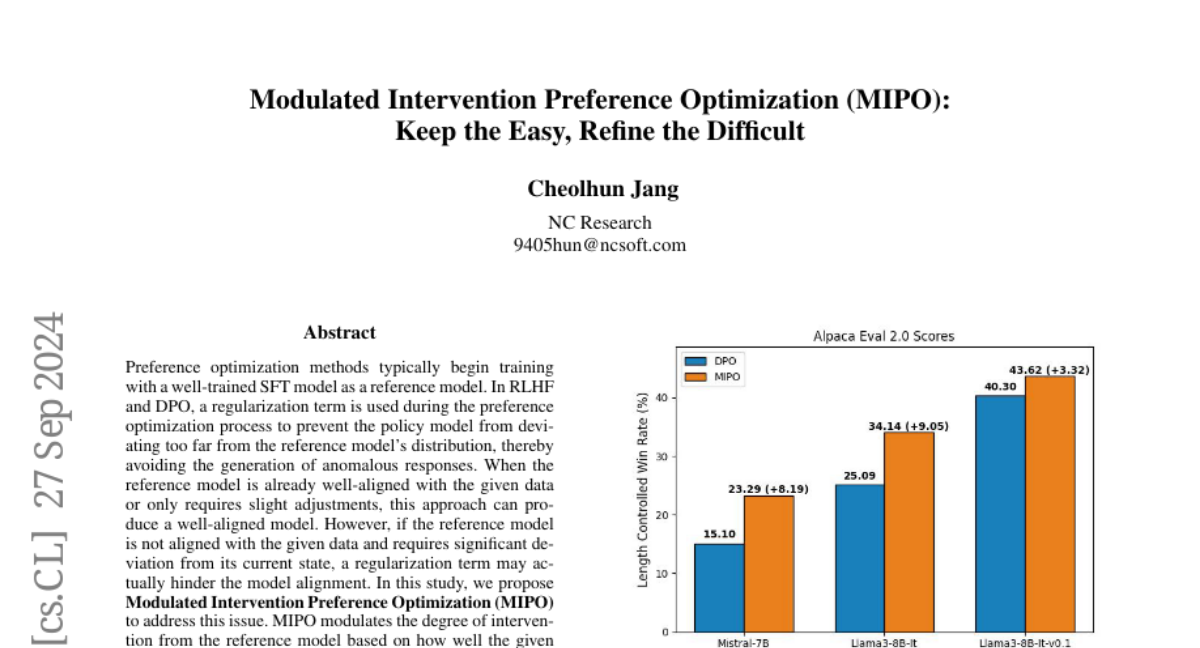
MIPO addresses this problem by changing the level of influence the reference model has during training. If the data is closely aligned with the reference model, MIPO increases its influence to maintain consistency. If the data is not well-aligned, MIPO decreases this influence, allowing for more flexibility in training. The authors tested MIPO against another method called DPO and found that MIPO performed better in various scenarios.
Why it matters?
This research is important because it helps improve how machine learning models learn from data. By making models more adaptable and better aligned with real-world information, MIPO can enhance their performance in tasks like natural language processing and decision-making, leading to more accurate and reliable AI systems.
Abstract
Preference optimization methods typically begin training with a well-trained SFT model as a reference model. In RLHF and DPO, a regularization term is used during the preference optimization process to prevent the policy model from deviating too far from the reference model's distribution, thereby avoiding the generation of anomalous responses. When the reference model is already well-aligned with the given data or only requires slight adjustments, this approach can produce a well-aligned model. However, if the reference model is not aligned with the given data and requires significant deviation from its current state, a regularization term may actually hinder the model alignment. In this study, we propose Modulated Intervention Preference Optimization (MIPO) to address this issue. MIPO modulates the degree of intervention from the reference model based on how well the given data is aligned with it. If the data is well-aligned, the intervention is increased to prevent the policy model from diverging significantly from reference model. Conversely, if the alignment is poor, the interference is reduced to facilitate more extensive training. We compare the performance of MIPO and DPO using Mistral-7B and Llama3-8B in Alpaca Eval 2.0 and MT-Bench. The experimental results demonstrate that MIPO consistently outperforms DPO across various evaluation scenarios.