No More Adam: Learning Rate Scaling at Initialization is All You Need
Minghao Xu, Lichuan Xiang, Xu Cai, Hongkai Wen
2024-12-19
Summary
This paper talks about a new optimization method called SGD-SaI, which improves the training of deep learning models by adjusting learning rates at the start without needing complex algorithms like Adam.
What's the problem?
Many deep learning models rely on adaptive gradient methods, like Adam, to adjust their learning rates during training. However, these methods can be memory-intensive and might not always perform well. This can lead to issues with training efficiency and effectiveness, especially when working with large models or datasets.
What's the solution?
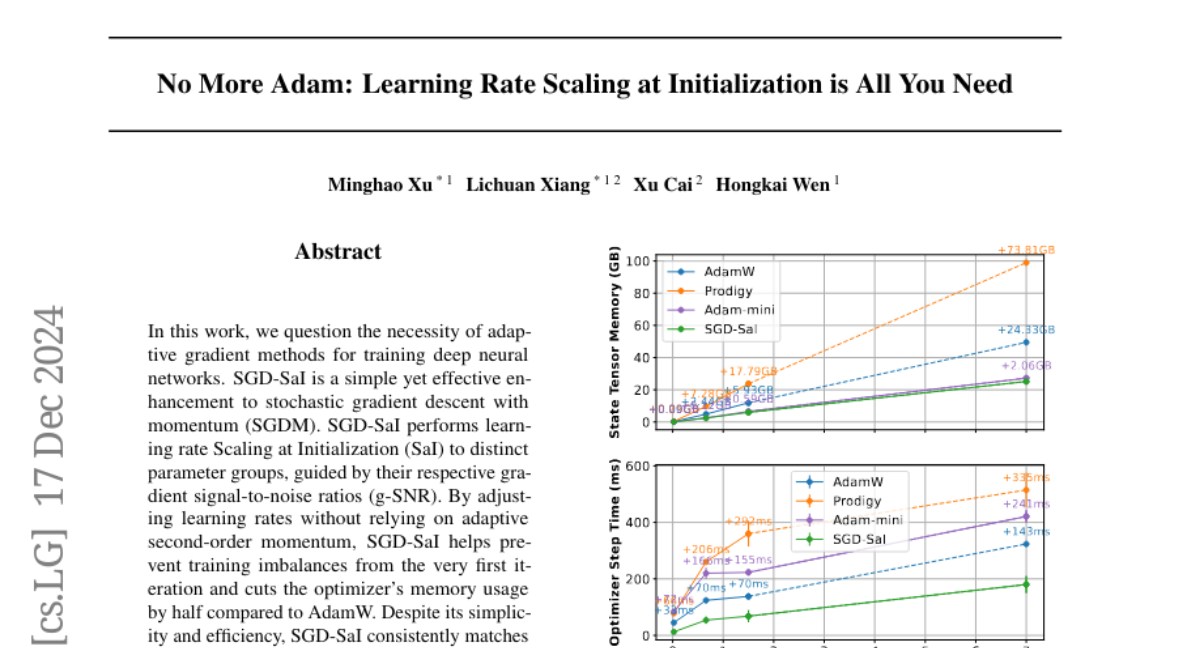
The authors propose SGD-SaI, a simpler method that focuses on scaling the learning rate at the beginning of training based on the gradient signal-to-noise ratio (g-SNR). This means that instead of using complex adjustments throughout training, SGD-SaI sets appropriate learning rates for different parts of the model right from the start. The results show that this approach not only saves memory but also matches or outperforms Adam in various tasks, including training large models like Vision Transformers and GPT-2.
Why it matters?
This research is important because it offers a more efficient way to train deep learning models, making it easier and less resource-intensive for researchers and developers. By simplifying the optimization process, SGD-SaI could help accelerate advancements in AI technologies, allowing for faster experimentation and deployment of powerful models.
Abstract
In this work, we question the necessity of adaptive gradient methods for training deep neural networks. SGD-SaI is a simple yet effective enhancement to stochastic gradient descent with momentum (SGDM). SGD-SaI performs learning rate Scaling at Initialization (SaI) to distinct parameter groups, guided by their respective gradient signal-to-noise ratios (g-SNR). By adjusting learning rates without relying on adaptive second-order momentum, SGD-SaI helps prevent training imbalances from the very first iteration and cuts the optimizer's memory usage by half compared to AdamW. Despite its simplicity and efficiency, SGD-SaI consistently matches or outperforms AdamW in training a variety of Transformer-based tasks, effectively overcoming a long-standing challenge of using SGD for training Transformers. SGD-SaI excels in ImageNet-1K classification with Vision Transformers(ViT) and GPT-2 pretraining for large language models (LLMs, transformer decoder-only), demonstrating robustness to hyperparameter variations and practicality for diverse applications. We further tested its robustness on tasks like LoRA fine-tuning for LLMs and diffusion models, where it consistently outperforms state-of-the-art optimizers. From a memory efficiency perspective, SGD-SaI achieves substantial memory savings for optimizer states, reducing memory usage by 5.93 GB for GPT-2 (1.5B parameters) and 25.15 GB for Llama2-7B compared to AdamW in full-precision training settings.