NormalCrafter: Learning Temporally Consistent Normals from Video Diffusion Priors
Yanrui Bin, Wenbo Hu, Haoyuan Wang, Xinya Chen, Bing Wang
2025-04-16
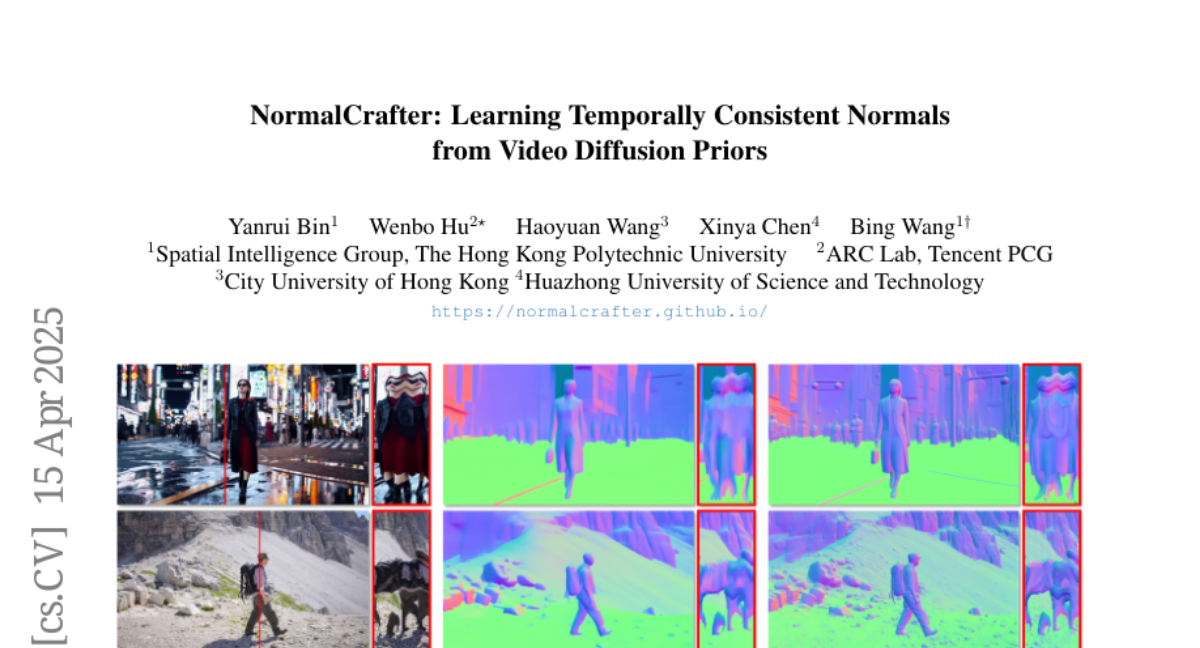
Summary
This paper talks about NormalCrafter, a new AI method that helps computers better understand the 3D shapes and surfaces in videos by making sure their predictions stay consistent from one frame to the next.
What's the problem?
The problem is that when AI tries to figure out the 3D surface details, called normals, in every frame of a video, the results can jump around and look unstable. This makes it hard to use these predictions for things like animation, robotics, or special effects, where smooth and consistent 3D information is really important.
What's the solution?
The researchers created NormalCrafter, which uses a special video diffusion model along with a process called Semantic Feature Regularization and a two-stage training method. This approach helps the AI learn from both the overall video and the details in each frame, so it can predict 3D surface normals that are smooth and steady throughout the whole video.
Why it matters?
This matters because having more stable and accurate 3D information from videos can make computer graphics, virtual reality, and robotics work much better. It helps create more realistic animations, improves how robots see and interact with the world, and makes special effects in movies and games look more natural.
Abstract
A novel method, NormalCrafter, enhances temporal coherence in video-based surface normal estimation by utilizing video diffusion models with Semantic Feature Regularization and two-stage training in latent and pixel spaces.