NVComposer: Boosting Generative Novel View Synthesis with Multiple Sparse and Unposed Images
Lingen Li, Zhaoyang Zhang, Yaowei Li, Jiale Xu, Xiaoyu Li, Wenbo Hu, Weihao Cheng, Jinwei Gu, Tianfan Xue, Ying Shan
2024-12-05
Summary
This paper introduces NVComposer, a new method for creating novel views of images from multiple sparse and unposed images without needing complicated alignment processes.
What's the problem?
Existing methods for generating new views of images often require precise alignment of multiple images, which can be difficult when the images don't overlap well or when there are obstructions. This reliance on external alignment makes it hard to use these methods in flexible situations, limiting their accessibility and effectiveness.
What's the solution?
NVComposer solves this problem by allowing the generative model to automatically understand the spatial and geometric relationships between different images without needing explicit alignment. It uses two key components: a dual-stream diffusion model that generates new views while also understanding camera positions, and a feature alignment module that learns geometric information from dense stereo models during training. This approach enables the model to create high-quality images even when the input images are sparse or unposed.
Why it matters?
This research is important because it enhances the ability of AI systems to generate realistic images from limited data, making it easier to create new perspectives in various applications like virtual reality, gaming, and film production. By removing the need for complicated alignment processes, NVComposer opens up new possibilities for creative content generation and improves accessibility for developers and researchers.
Abstract
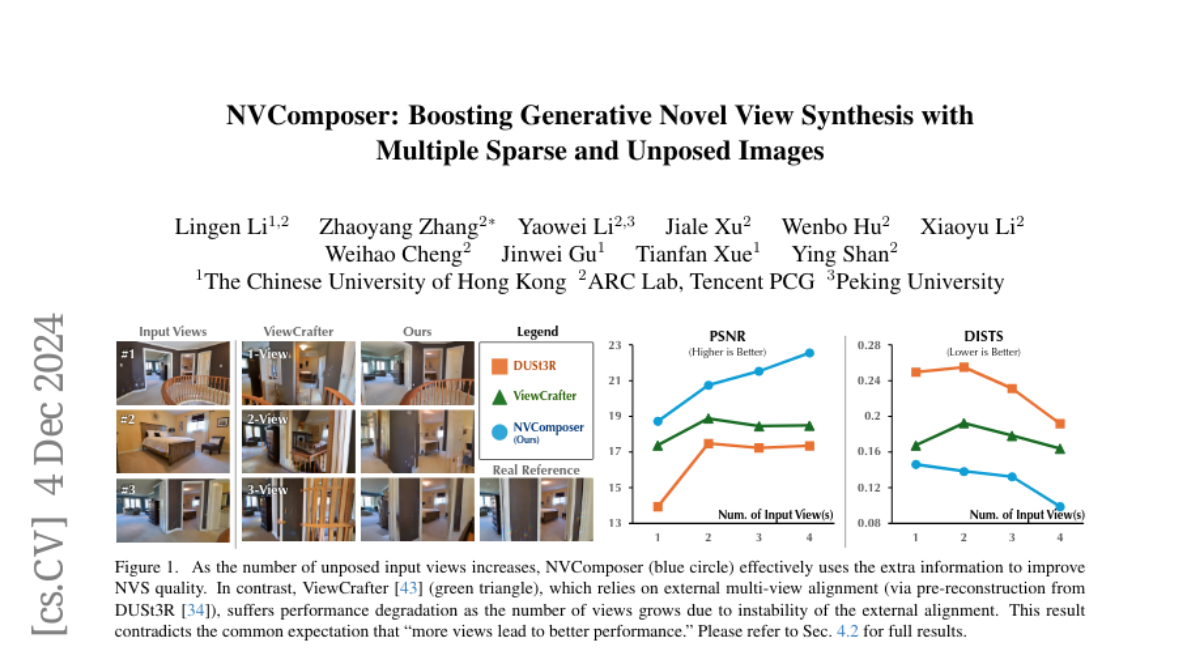
Recent advancements in generative models have significantly improved novel view synthesis (NVS) from multi-view data. However, existing methods depend on external multi-view alignment processes, such as explicit pose estimation or pre-reconstruction, which limits their flexibility and accessibility, especially when alignment is unstable due to insufficient overlap or occlusions between views. In this paper, we propose NVComposer, a novel approach that eliminates the need for explicit external alignment. NVComposer enables the generative model to implicitly infer spatial and geometric relationships between multiple conditional views by introducing two key components: 1) an image-pose dual-stream diffusion model that simultaneously generates target novel views and condition camera poses, and 2) a geometry-aware feature alignment module that distills geometric priors from dense stereo models during training. Extensive experiments demonstrate that NVComposer achieves state-of-the-art performance in generative multi-view NVS tasks, removing the reliance on external alignment and thus improving model accessibility. Our approach shows substantial improvements in synthesis quality as the number of unposed input views increases, highlighting its potential for more flexible and accessible generative NVS systems.