OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn
2024-06-14
Summary
This paper introduces OpenVLA, a new open-source model that helps robots learn to perform tasks by combining vision, language, and action. It is designed to improve how robots understand instructions and interact with their environment.
What's the problem?
Teaching robots new skills can be difficult because most existing models are closed and not available for public use. Additionally, previous methods for training these models on new tasks have not been efficient, making it hard to adapt them for different situations. This limits the potential for widespread use of vision-language-action (VLA) models in robotics.
What's the solution?
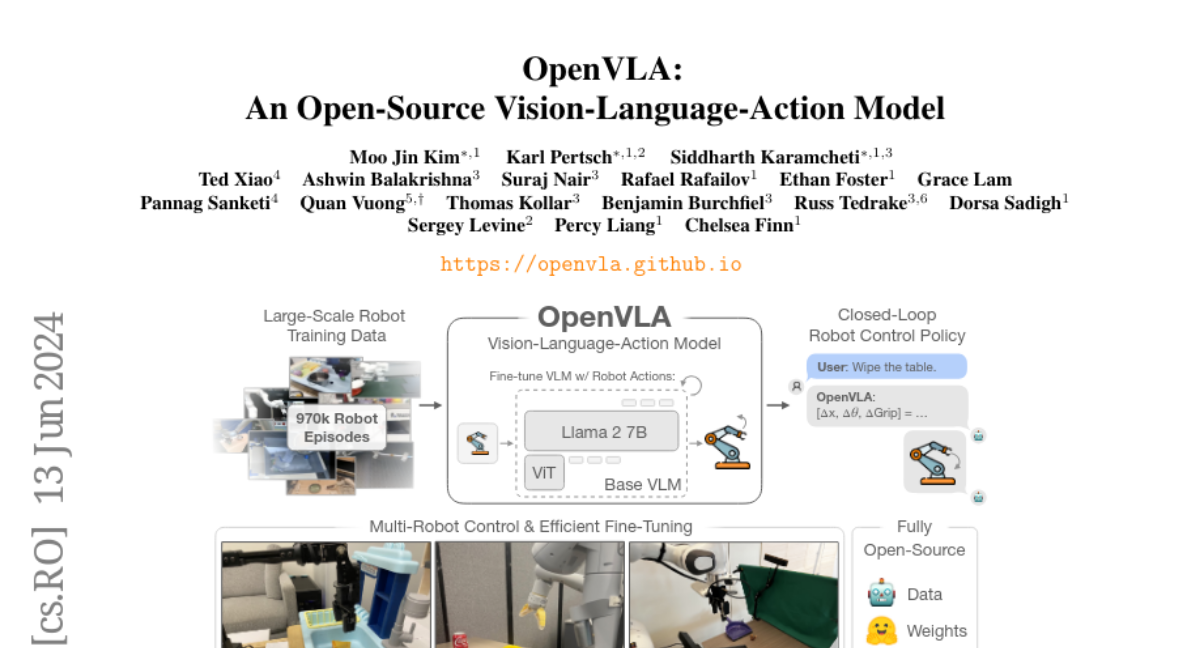
OpenVLA addresses these challenges by being an open-source model trained on a large dataset of 970,000 real-world robot demonstrations. It combines a powerful language model (Llama 2) with visual features from other advanced models (DINOv2 and SigLIP). This combination allows OpenVLA to perform better than other models, achieving higher success rates in various tasks while using fewer parameters. The model can also be fine-tuned easily for new tasks, making it adaptable and efficient.
Why it matters?
This research is important because it opens up access to advanced robotic learning tools that can be used by researchers and developers. By improving how robots learn from both visual data and language instructions, OpenVLA has the potential to enhance robotic applications in many areas, such as manufacturing, healthcare, and everyday assistance, ultimately making robots more capable and versatile.
Abstract
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.