Optimizing Anytime Reasoning via Budget Relative Policy Optimization
Penghui Qi, Zichen Liu, Tianyu Pang, Chao Du, Wee Sun Lee, Min Lin
2025-05-21
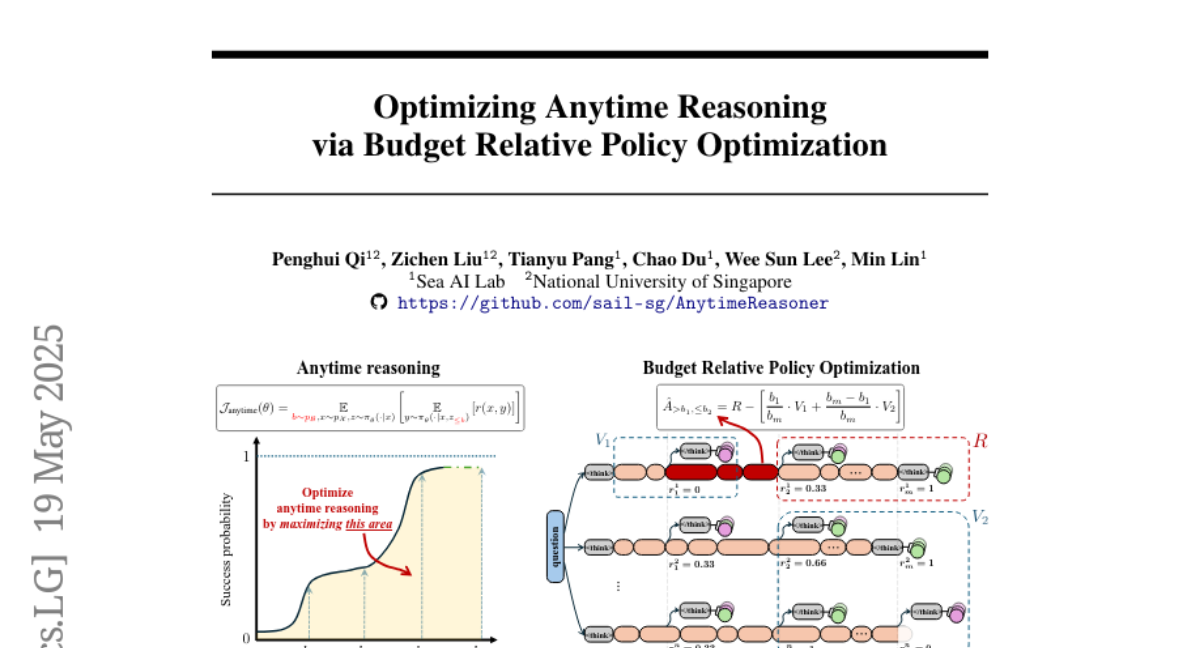
Summary
This paper talks about AnytimeReasoner, a new system that helps big AI language models think and solve problems more efficiently, especially when they have limited time or computer resources.
What's the problem?
The problem is that large language models can take a lot of time and computational power to reason through complex questions, which isn't always practical when quick answers are needed or resources are tight.
What's the solution?
To solve this, the researchers introduced a method that gives the AI clear, measurable rewards for being efficient with its words and reasoning steps. They also separated the way the AI learns to make decisions from the way it manages its resources, allowing it to adapt better to different situations and budgets.
Why it matters?
This matters because it means AI can provide useful answers faster and with less cost, making advanced reasoning tools more practical for real-world use in everything from homework help to business decisions.
Abstract
The AnytimeReasoner framework optimizes token efficiency and reasoning flexibility for large language models by introducing verifiable dense rewards and a decoupled policy optimization technique.