Orthogonal Finetuning Made Scalable
Zeju Qiu, Weiyang Liu, Adrian Weller, Bernhard Schölkopf
2025-06-25
Summary
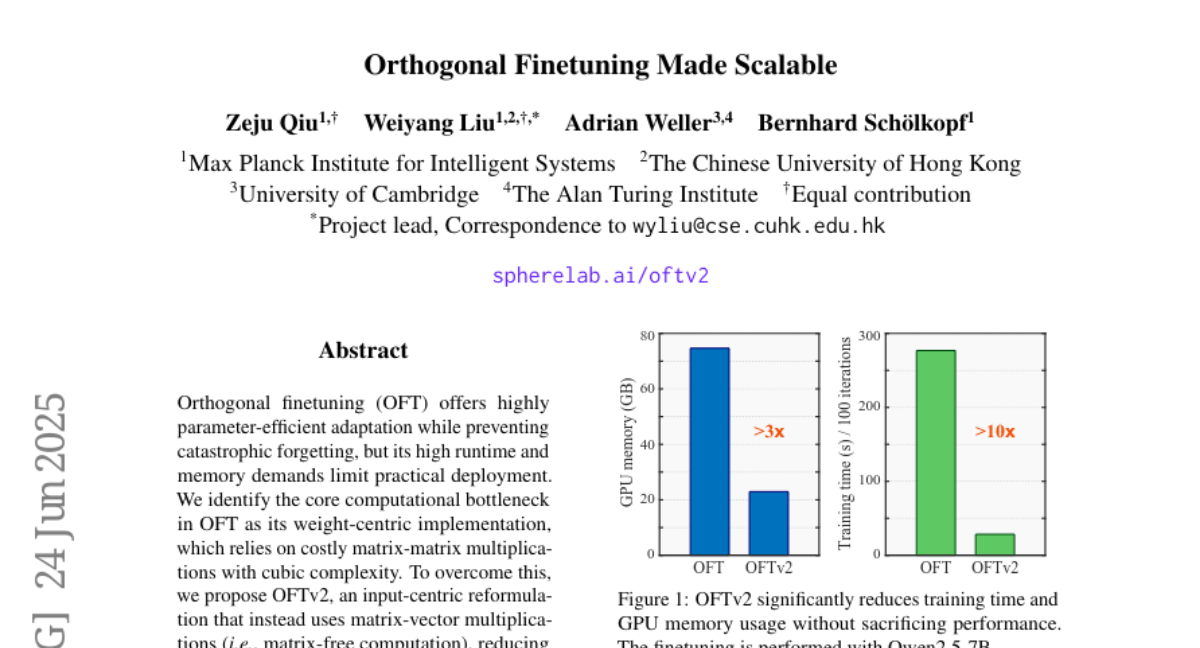
This paper talks about Orthogonal Finetuning Made Scalable (OFTv2), an improved way to fine-tune large AI models by making a special math operation called orthogonal fine-tuning much faster and use less memory.
What's the problem?
The problem is that the original orthogonal fine-tuning method is very slow and uses a lot of computer memory because it works with big matrix-matrix multiplications, which become more expensive as the model size grows.
What's the solution?
The researchers changed the method to work with matrix-vector multiplications instead, applying transformations directly to input vectors instead of combining big matrices. They also introduced a new parameterization technique called Cayley-Neumann that makes the process more efficient, which significantly speeds up training and reduces memory use.
Why it matters?
This matters because it allows researchers and developers to fine-tune huge AI models much more efficiently, making it easier to adapt these powerful models to new tasks without needing super expensive computing resources.
Abstract
OFTv2 optimizes orthogonal fine-tuning by shifting from matrix-matrix to matrix-vector multiplications and introducing efficient Cayley-Neumann parameterization, enhancing speed, memory usage, and performance.