OutfitAnyone: Ultra-high Quality Virtual Try-On for Any Clothing and Any Person
Ke Sun, Jian Cao, Qi Wang, Linrui Tian, Xindi Zhang, Lian Zhuo, Bang Zhang, Liefeng Bo, Wenbo Zhou, Weiming Zhang, Daiheng Gao
2024-07-24
Summary
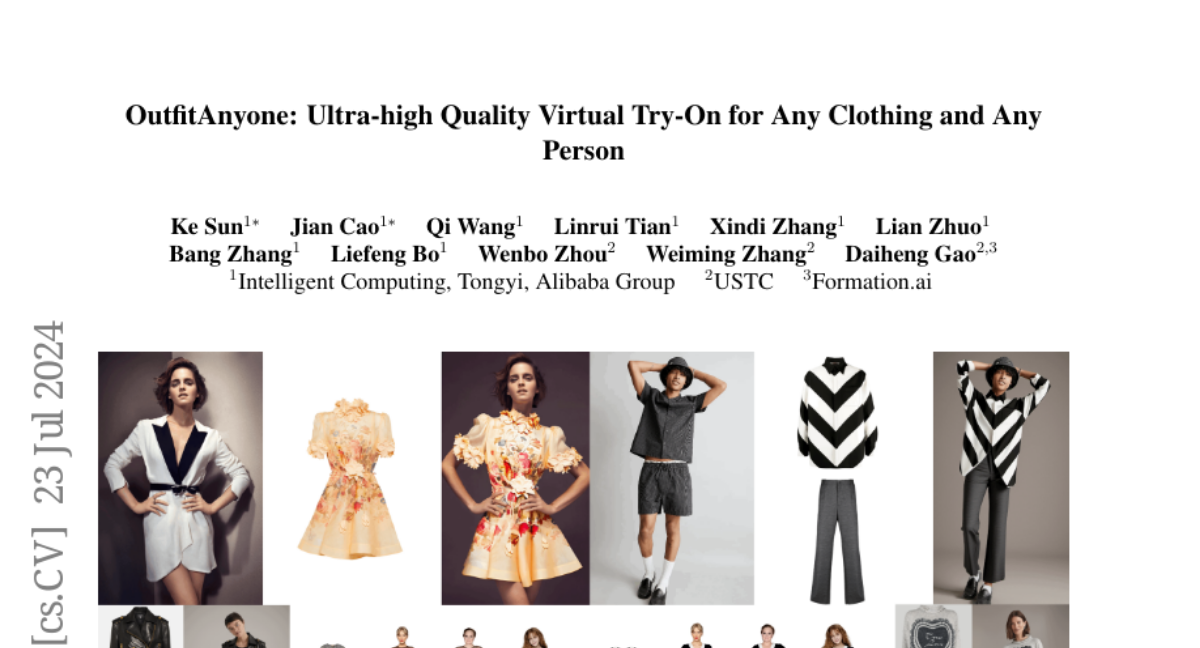
This paper introduces OutfitAnyone, a cutting-edge virtual try-on technology that allows users to see how any clothing item looks on any person without physically trying it on. It aims to provide ultra-high quality and realistic virtual fitting experiences.
What's the problem?
Current virtual try-on (VTON) methods often struggle to create realistic and detailed images of clothing on different body types. Many existing models have difficulty maintaining the fit and appearance of garments, especially when the clothing needs to adapt to various poses and body shapes. This can lead to poor-quality results that do not accurately represent how the clothing would look in real life.
What's the solution?
OutfitAnyone addresses these challenges by using a two-stream conditional diffusion model that effectively manages how clothing deforms and fits different body types. This model allows for high-quality image generation by processing garment and model data separately before combining them. Additionally, it incorporates features like pose and body shape adjustments, making it versatile enough to work with a wide range of styles, from anime characters to real-life images. The system also includes a refinement step that enhances the texture and realism of the clothing in the final images.
Why it matters?
This research is important because it significantly improves the virtual try-on experience, making it more accessible and realistic for users. By allowing people to experiment with fashion without the hassle of changing rooms or physical limitations, OutfitAnyone can transform online shopping and personal styling. It also promotes inclusivity by accommodating various body shapes, ensuring that everyone can find outfits that fit them well.
Abstract
Virtual Try-On (VTON) has become a transformative technology, empowering users to experiment with fashion without ever having to physically try on clothing. However, existing methods often struggle with generating high-fidelity and detail-consistent results. While diffusion models, such as Stable Diffusion series, have shown their capability in creating high-quality and photorealistic images, they encounter formidable challenges in conditional generation scenarios like VTON. Specifically, these models struggle to maintain a balance between control and consistency when generating images for virtual clothing trials. OutfitAnyone addresses these limitations by leveraging a two-stream conditional diffusion model, enabling it to adeptly handle garment deformation for more lifelike results. It distinguishes itself with scalability-modulating factors such as pose, body shape and broad applicability, extending from anime to in-the-wild images. OutfitAnyone's performance in diverse scenarios underscores its utility and readiness for real-world deployment. For more details and animated results, please see https://humanaigc.github.io/outfit-anyone/.