PoseLess: Depth-Free Vision-to-Joint Control via Direct Image Mapping with VLM
Alan Dao, Dinh Bach Vu, Tuan Le Duc Anh, Bui Quang Huy
2025-03-14
Summary
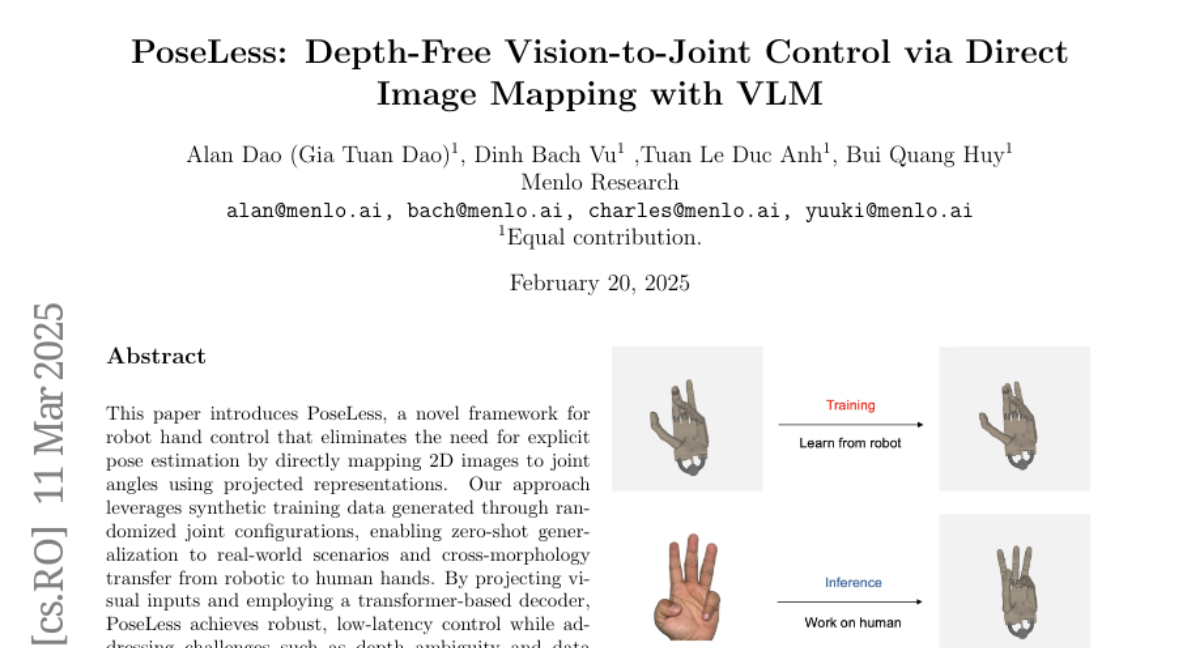
This paper introduces PoseLess, a new way to control robot hands using only images, without needing to figure out the hand's exact position.
What's the problem?
Controlling robot hands usually requires complex systems to estimate the hand's position in 3D space. This can be difficult and requires lots of data.
What's the solution?
PoseLess directly translates 2D images into the angles of the robot's joints, skipping the step of figuring out the 3D position. It's trained on fake (synthetic) data, which allows it to work in real-world situations and even control human hands.
Why it matters?
This work matters because it simplifies robot hand control, making it faster, more efficient, and able to work in diverse environments without needing extensive real-world data.
Abstract
This paper introduces PoseLess, a novel framework for robot hand control that eliminates the need for explicit pose estimation by directly mapping 2D images to joint angles using projected representations. Our approach leverages synthetic training data generated through randomized joint configurations, enabling zero-shot generalization to real-world scenarios and cross-morphology transfer from robotic to human hands. By projecting visual inputs and employing a transformer-based decoder, PoseLess achieves robust, low-latency control while addressing challenges such as depth ambiguity and data scarcity. Experimental results demonstrate competitive performance in joint angle prediction accuracy without relying on any human-labelled dataset.