Predicting Rewards Alongside Tokens: Non-disruptive Parameter Insertion for Efficient Inference Intervention in Large Language Model
Chenhan Yuan, Fei Huang, Ru Peng, Keming Lu, Bowen Yu, Chang Zhou, Jingren Zhou
2024-08-21
Summary
This paper discusses a new method called Otter that helps improve how large language models (LLMs) make decisions by predicting rewards alongside their outputs without needing extra training.
What's the problem?
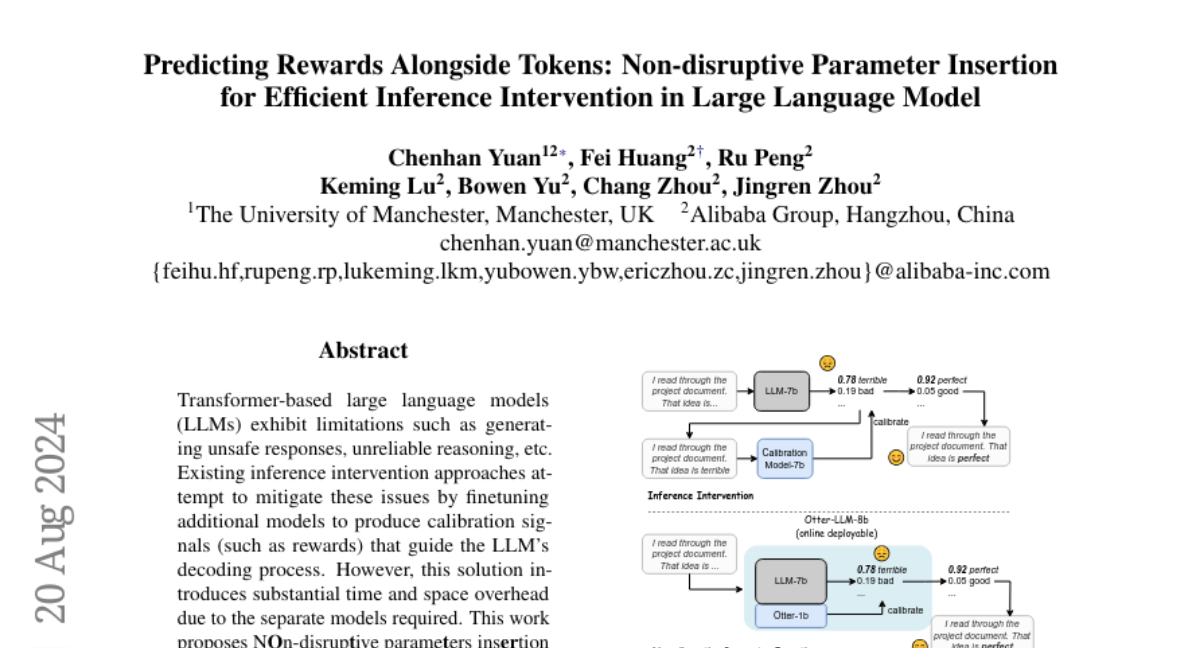
Large language models can sometimes produce unsafe or incorrect responses, and existing methods to fix these issues often require additional models that take up a lot of time and space. This makes it hard to efficiently improve the model's performance during real-time use.
What's the solution?
Otter solves this problem by inserting extra parameters directly into the existing model architecture. This allows the model to predict helpful signals (rewards) while generating its usual output. By doing this, Otter can enhance the model's performance significantly while using much less computational power and time compared to previous methods. It integrates easily with existing systems, needing only a simple code change.
Why it matters?
This research is important because it makes it easier and faster to improve the safety and reliability of language models. By reducing the resources needed for intervention, Otter can help ensure that AI systems provide better responses in real-world applications, which is crucial as these technologies become more widely used.
Abstract
Transformer-based large language models (LLMs) exhibit limitations such as generating unsafe responses, unreliable reasoning, etc. Existing inference intervention approaches attempt to mitigate these issues by finetuning additional models to produce calibration signals (such as rewards) that guide the LLM's decoding process. However, this solution introduces substantial time and space overhead due to the separate models required. This work proposes Non-disruptive parameters insertion (Otter), inserting extra parameters into the transformer architecture to predict calibration signals along with the original LLM output. Otter offers state-of-the-art performance on multiple demanding tasks while saving up to 86.5\% extra space and 98.5\% extra time. Furthermore, Otter seamlessly integrates with existing inference engines, requiring only a one-line code change, and the original model response remains accessible after the parameter insertion. Our code is publicly available at https://github.com/chenhan97/Otter