R1-RE: Cross-Domain Relationship Extraction with RLVR
Runpeng Dai, Tong Zheng, Run Yang, Hongtu Zhu
2025-07-08
Summary
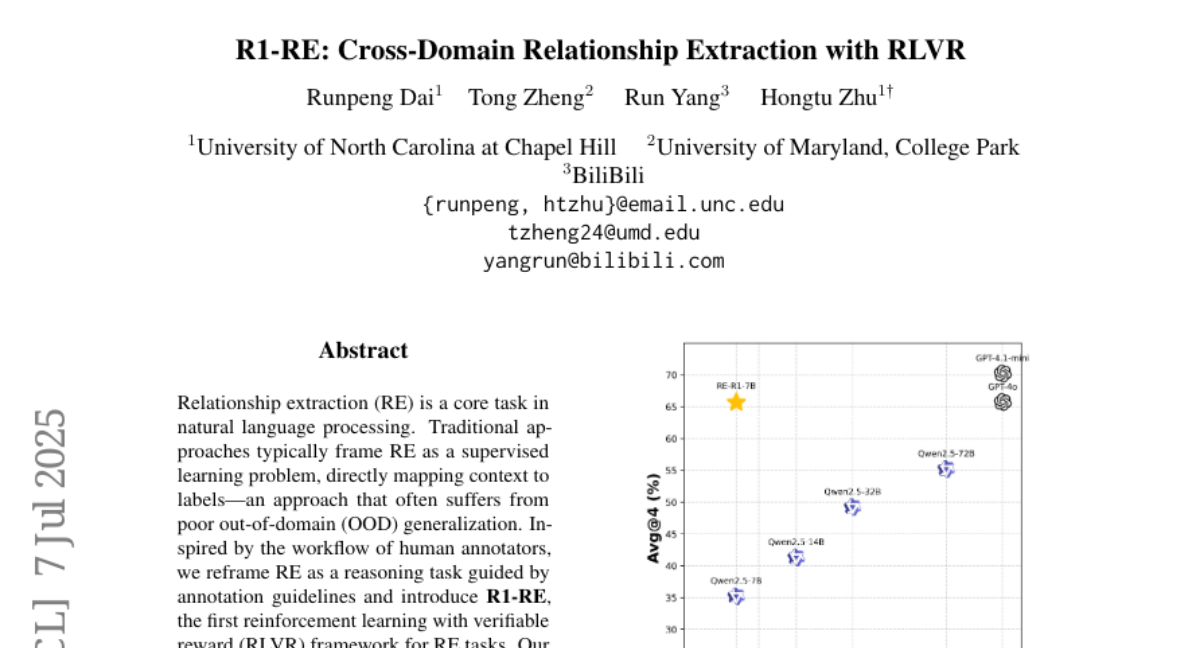
This paper talks about R1-RE, a new method for relationship extraction in natural language processing that uses reinforcement learning with verifiable rewards. It mimics how humans use guidelines and reasoning to identify relationships between entities in text.
What's the problem?
The problem is that traditional methods treat relationship extraction as a simple mapping from sentences to labels, which works poorly when applied to new or different domains because the models don’t generalize well.
What's the solution?
The researchers designed R1-RE to follow a step-by-step reasoning process inspired by human annotators who consult annotation guides. This method uses smaller language models in a reinforcement learning framework that rewards correct and verifiable reasoning steps, greatly improving performance on data from different domains.
Why it matters?
This matters because better relationship extraction helps AI understand connections and information in text more reliably across many fields, improving tasks like information retrieval, knowledge base construction, and more general natural language understanding.
Abstract
R1-RE, a reinforcement learning with verifiable reward framework, enhances out-of-domain robustness in relationship extraction by leveraging small language models and annotation guidelines.