ReMamba: Equip Mamba with Effective Long-Sequence Modeling
Danlong Yuan, Jiahao Liu, Bei Li, Huishuai Zhang, Jingang Wang, Xunliang Cai, Dongyan Zhao
2024-08-29
Summary
This paper discusses ReMamba, a new version of the Mamba model that improves its ability to understand long sequences of text.
What's the problem?
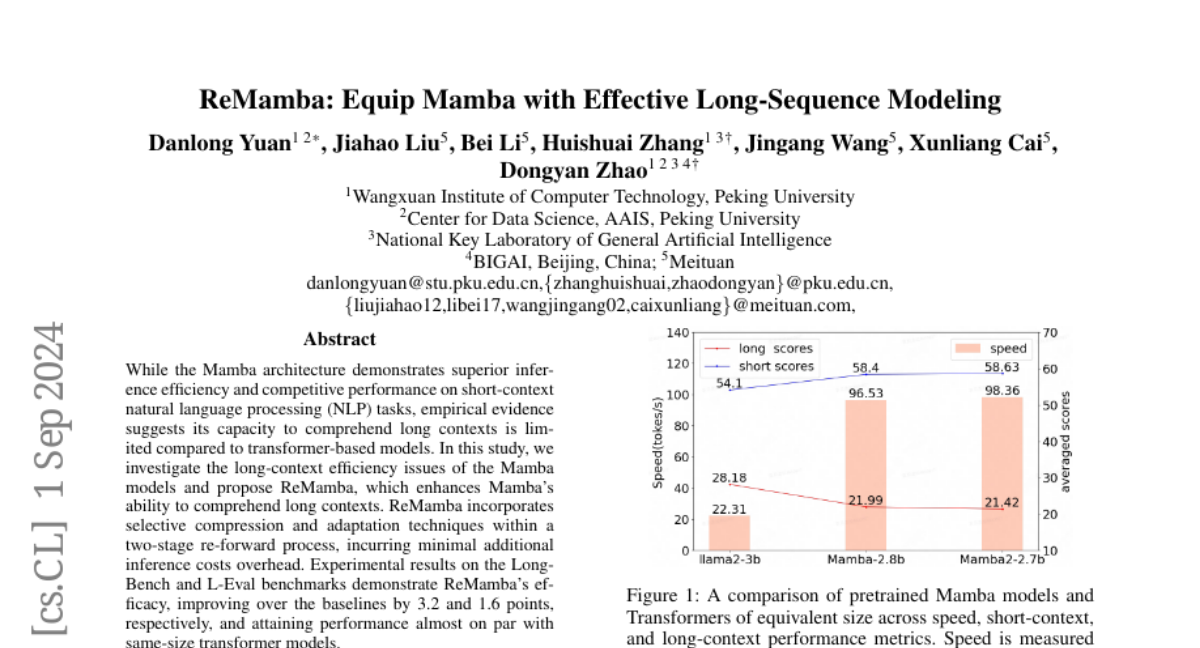
The original Mamba model is great for processing short texts quickly, but it struggles with longer texts compared to other models like transformers. This limitation can hinder its effectiveness in tasks that require understanding complex or lengthy information.
What's the solution?
ReMamba enhances the Mamba model's performance with long sequences by using a two-stage process that includes selective compression and adaptation techniques. This means it can better handle longer contexts without significantly increasing the time or resources needed for processing. The researchers conducted experiments that showed ReMamba performs better on benchmarks designed for long-context tasks, achieving scores that are almost as good as larger transformer models.
Why it matters?
This research is important because it helps improve how language models work with longer texts, making them more versatile for various applications like reading comprehension, summarization, and more complex natural language processing tasks. By enhancing the capabilities of models like ReMamba, we can develop smarter AI systems that understand and generate human-like text more effectively.
Abstract
While the Mamba architecture demonstrates superior inference efficiency and competitive performance on short-context natural language processing (NLP) tasks, empirical evidence suggests its capacity to comprehend long contexts is limited compared to transformer-based models. In this study, we investigate the long-context efficiency issues of the Mamba models and propose ReMamba, which enhances Mamba's ability to comprehend long contexts. ReMamba incorporates selective compression and adaptation techniques within a two-stage re-forward process, incurring minimal additional inference costs overhead. Experimental results on the LongBench and L-Eval benchmarks demonstrate ReMamba's efficacy, improving over the baselines by 3.2 and 1.6 points, respectively, and attaining performance almost on par with same-size transformer models.