REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, Liang Zheng
2025-04-17
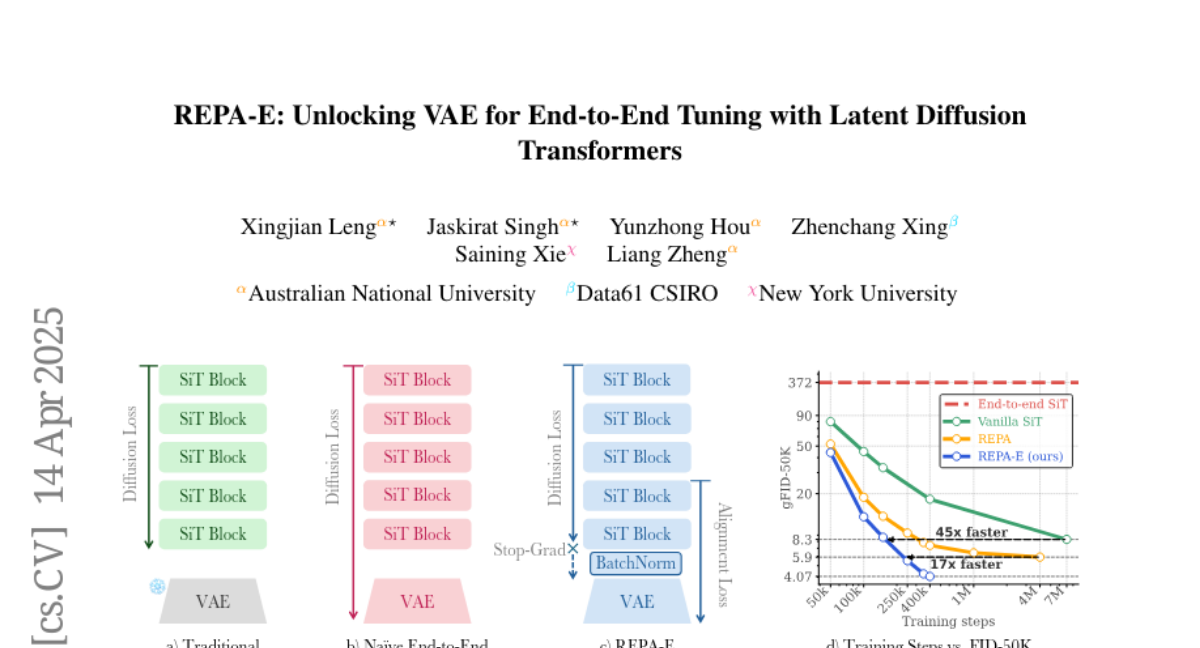
Summary
This paper talks about REPA-E, a new way to train AI models that generate images by combining two important parts, the VAE (which compresses images into simpler forms) and the diffusion model (which creates images from noise), so they work better together and train faster.
What's the problem?
The problem is that in most current systems, the VAE and the diffusion model are trained separately, which can cause them to not work perfectly together. This makes the whole process slower and can lead to lower quality results because the two parts aren't fully aligned in how they represent and process images.
What's the solution?
The researchers introduced a way to train both the VAE and the diffusion model at the same time, using a special loss called representation-alignment loss. This makes sure the VAE's compressed codes and the diffusion model's generation process are in sync, leading to faster training and better performance from both parts.
Why it matters?
This matters because it makes image-generating AI models more efficient and higher quality, which is important for applications like art, design, and any technology that needs to quickly create realistic images from simple inputs.
Abstract
End-to-end training of latent diffusion models and VAE tokenizers using representation-alignment loss enhances diffusion model training speed and VAE performance.