Rethinking the Generation of High-Quality CoT Data from the Perspective of LLM-Adaptive Question Difficulty Grading
Qianjin Yu, Keyu Wu, Zihan Chen, Chushu Zhang, Manlin Mei, Lingjun Huang, Fang Tan, Yongsheng Du, Kunlin Liu, Yurui Zhu
2025-04-24
Summary
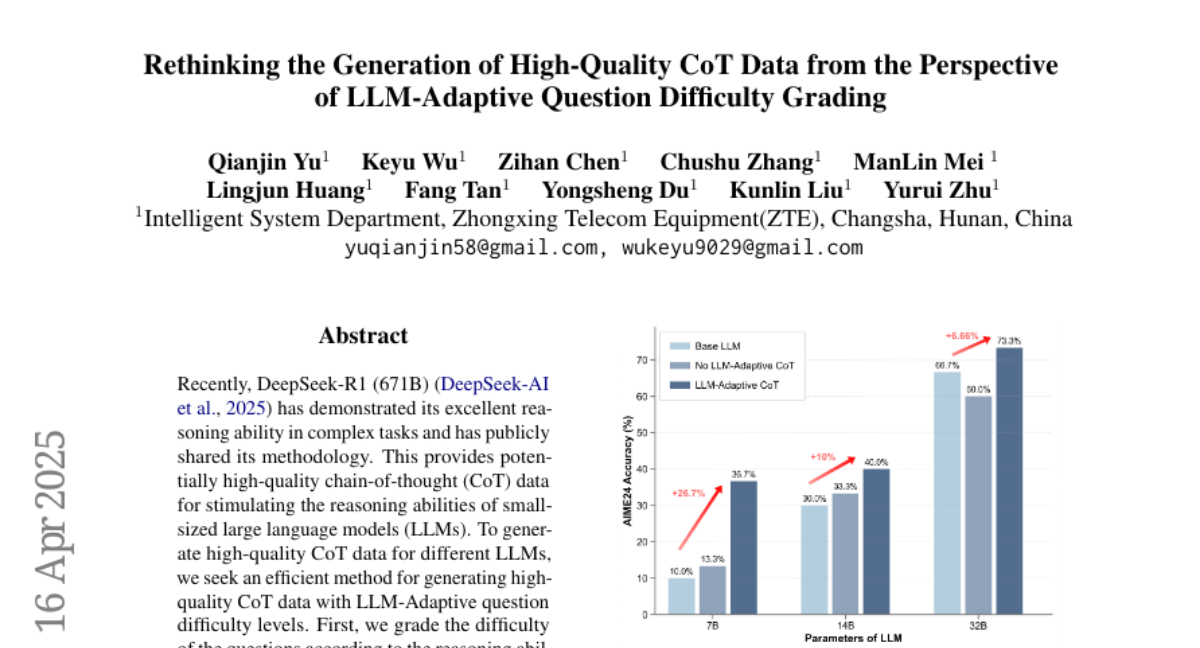
This paper talks about a new way to create better training data for AI models by adjusting the difficulty of questions to match what the model can handle, which helps the model learn to solve tough problems step by step.
What's the problem?
The problem is that when training large language models to reason through complicated tasks, like solving math problems or writing code, the examples they learn from are often too easy, too hard, or not well suited for the model's current abilities. This makes it harder for the AI to improve at complex reasoning.
What's the solution?
The researchers developed a method that grades the difficulty of questions and then generates step-by-step explanations, called chain-of-thought data, that are just right for the model’s level. This way, the model gets practice on questions that are challenging but not impossible, which helps it get better at reasoning through complicated tasks.
Why it matters?
This matters because it means AI can become much better at solving real-world problems that require multiple steps and careful thinking, making these models more useful for things like advanced math, programming, and other areas where deep reasoning is important.
Abstract
The proposed method generates LLM-Adaptive chain-of-thought data for efficient supervised fine-tuning, improving model performance in complex reasoning tasks like mathematics and code generation.