RLPR: Extrapolating RLVR to General Domains without Verifiers
Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, Maosong Sun, Tat-Seng Chua
2025-06-24
Summary
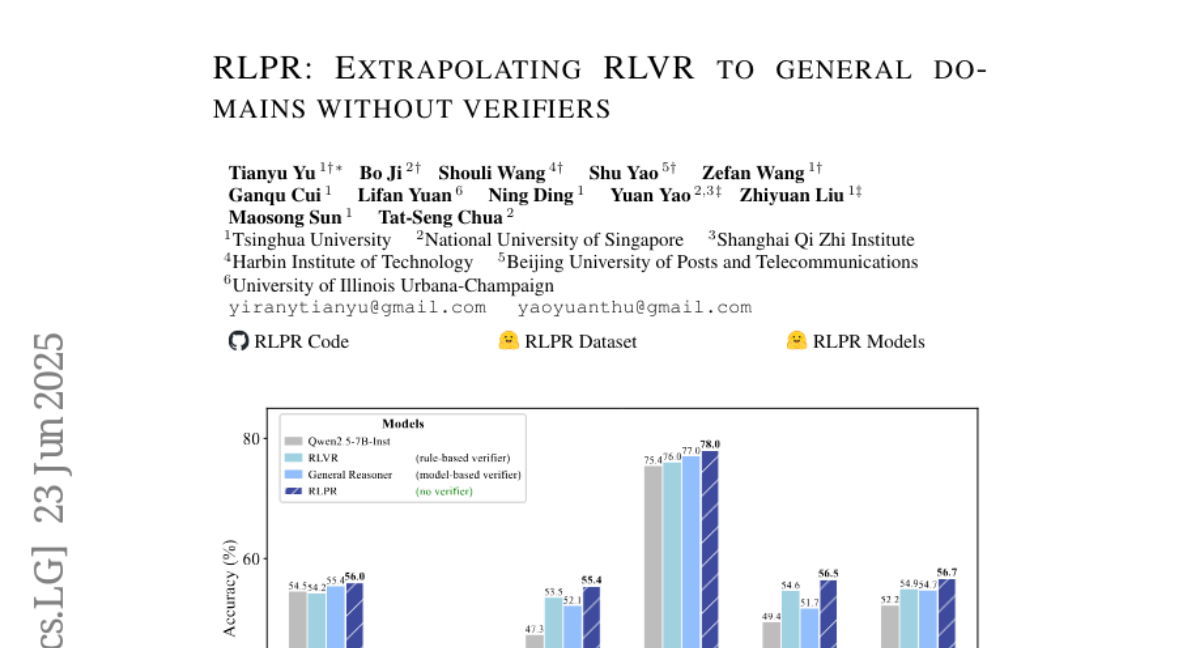
This paper talks about RLPR, a new AI framework that improves reasoning abilities across different fields by using large language models' token prediction scores as rewards without needing extra verifier tools.
What's the problem?
The problem is that many reinforcement learning methods for language models rely on external verifiers to check if the outputs are correct, which can be slow, limited, or unavailable for some tasks.
What's the solution?
The researchers created RLPR, which uses the large language model's own token probability scores as feedback to guide learning. This removes the need for separate verifiers and helps the model improve its reasoning in both general knowledge and math problems.
Why it matters?
This matters because it makes AI reasoning more flexible and powerful across different tasks, simplifying the training process and boosting performance where external verification is difficult or impossible.
Abstract
RLPR, a verifier-free framework using LLM's token probability scores as reward signals, enhances reasoning capabilities across both general and mathematical domains, outperforming other methods in various benchmarks.