Safety Arithmetic: A Framework for Test-time Safety Alignment of Language Models by Steering Parameters and Activations
Rima Hazra, Sayan Layek, Somnath Banerjee, Soujanya Poria
2024-06-19
Summary
This paper introduces Safety Arithmetic, a new framework designed to improve the safety of large language models (LLMs) like those used in translation and question answering. It aims to ensure that these models align better with human values and avoid generating harmful content.
What's the problem?
As LLMs are increasingly used in various applications, ensuring they produce safe and appropriate responses is crucial. However, existing methods for aligning these models often struggle to adapt to changing user needs and complex situations. This can lead to the models unintentionally generating harmful or inappropriate content, which poses risks to users and society.
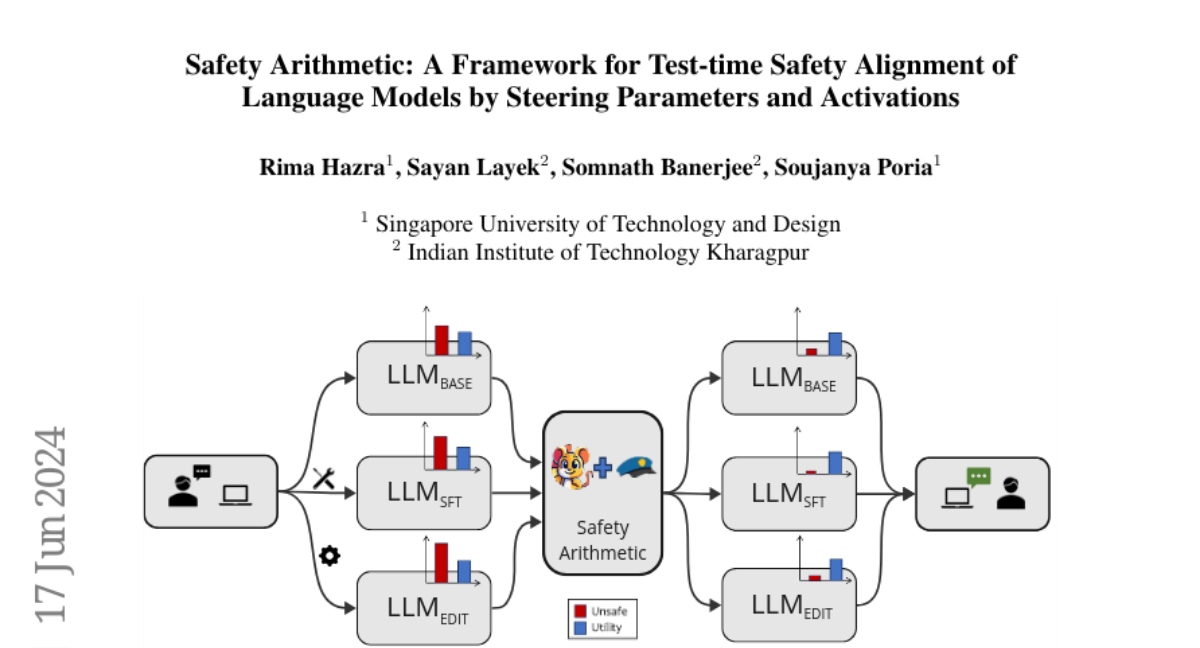
What's the solution?
The authors propose Safety Arithmetic, which is a training-free approach that enhances the safety of LLMs without needing additional training. This framework includes techniques like Harm Direction Removal, which helps prevent harmful outputs, and Safety Alignment, which encourages the generation of safe responses. The paper also introduces a dataset called NoIntentEdit, which highlights instances where edits could compromise safety if not handled carefully. Through experiments, the authors demonstrate that Safety Arithmetic improves safety measures while still allowing the model to function effectively.
Why it matters?
This research is important because it addresses a critical issue in the deployment of AI systems. By improving how LLMs align with human values and ensuring they produce safe content, Safety Arithmetic can help make AI applications more reliable and trustworthy. This advancement is essential as AI becomes more integrated into everyday life, ensuring that it serves users positively and ethically.
Abstract
Ensuring the safe alignment of large language models (LLMs) with human values is critical as they become integral to applications like translation and question answering. Current alignment methods struggle with dynamic user intentions and complex objectives, making models vulnerable to generating harmful content. We propose Safety Arithmetic, a training-free framework enhancing LLM safety across different scenarios: Base models, Supervised fine-tuned models (SFT), and Edited models. Safety Arithmetic involves Harm Direction Removal to avoid harmful content and Safety Alignment to promote safe responses. Additionally, we present NoIntentEdit, a dataset highlighting edit instances that could compromise model safety if used unintentionally. Our experiments show that Safety Arithmetic significantly improves safety measures, reduces over-safety, and maintains model utility, outperforming existing methods in ensuring safe content generation.