Scale-Distribution Decoupling: Enabling Stable and Effective Training of Large Language Models
Ya Wang, Zhijian Zhuo, Yutao Zeng, Xun Zhou, Jian Yang, Xiaoqing Li
2025-02-26
Summary
This paper talks about a new method called Scale-Distribution Decoupling (SDD) that helps make training large AI language models more stable and effective
What's the problem?
Training big AI language models is tricky because the math behind them can get out of control. Sometimes the numbers get too big or too small, which makes it hard for the AI to learn properly. This is especially true for a type of AI model called Post-Norm Transformers
What's the solution?
The researchers created SDD, which separates two parts of the AI's math: the scale (how big the numbers are) and the distribution (how the numbers are spread out). SDD uses a special way to keep the numbers in check and a learnable scaling part to make sure the AI can still learn effectively. This helps prevent the numbers from getting too big or too small during training
Why it matters?
This matters because it makes training big AI language models easier and more reliable. It works with different types of AI models and performs better than other methods. Since it's simple to use and works with existing AI training setups, it could help researchers and companies create better AI language models more easily. This could lead to improvements in things like chatbots, translation services, and other AI tools that work with language
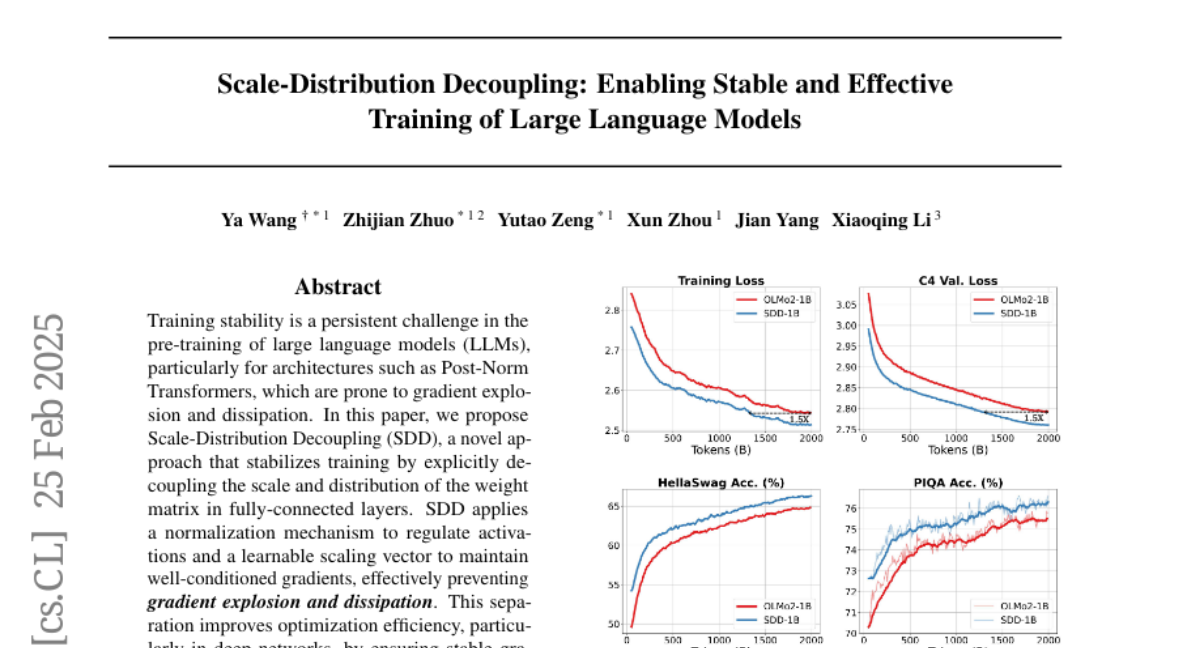
Abstract
Training stability is a persistent challenge in the pre-training of large language models (LLMs), particularly for architectures such as Post-Norm Transformers, which are prone to gradient explosion and dissipation. In this paper, we propose Scale-Distribution Decoupling (SDD), a novel approach that stabilizes training by explicitly decoupling the scale and distribution of the weight matrix in fully-connected layers. SDD applies a normalization mechanism to regulate activations and a learnable scaling vector to maintain well-conditioned gradients, effectively preventing gradient explosion and dissipation. This separation improves optimization efficiency, particularly in deep networks, by ensuring stable gradient propagation. Experimental results demonstrate that our method stabilizes training across various LLM architectures and outperforms existing techniques in different normalization configurations. Furthermore, the proposed method is lightweight and compatible with existing frameworks, making it a practical solution for stabilizing LLM training. Code is available at https://github.com/kaihemo/SDD.